Chapter 4 Coordination de processus
4.1 Problème
Modifions notre classe Compte afin de pouvoir faire des
opérations dessus, voir figure 4.1.
public class Banque implements Runnable {
Compte nom;
Banque(Compte n) {
nom = n; }
public void Liquide (int montant)
throws InterruptedException {
if (nom.retirer(montant)) {
Thread.currentThread().sleep(50);
Donne(montant);
Thread.currentThread().sleep(50); }
ImprimeRecu();
Thread.currentThread().sleep(50); }
public void Donne(int montant) {
System.out.println(Thread.currentThread().
getName()+": Voici vos " + montant + " francs."); }
public void ImprimeRecu() {
if (nom.solde() > 0)
System.out.println(Thread.currentThread().
getName()+": Il vous reste " + nom.solde() + " francs.");
else
System.out.println(Thread.currentThread().
getName()+": Vous etes fauches!");
}
public void run() {
try {
for (int i=1;i<10;i++) {
Liquide(100*i);
Thread.currentThread().sleep(100+10*i);
}
} catch (InterruptedException e) {
return;
}
}
public static void main(String[] args) {
Compte Commun = new Compte(1000);
Runnable Mari = new Banque(Commun);
Runnable Femme = new Banque(Commun);
Thread tMari = new Thread(Mari);
Thread tFemme = new Thread(Femme);
tMari.setName("Conseiller Mari");
tFemme.setName("Conseiller Femme");
tMari.start();
tFemme.start();
}
}
Figure 4.1:
Une exécution typique est la suivante:
% java Banque
Conseiller Mari: Voici vos 100 francs.
Conseiller Femme: Voici vos 100 francs.
Conseiller Mari: Il vous reste 800 francs.
Conseiller Femme: Il vous reste 800 francs.
Conseiller Mari: Voici vos 200 francs.
Conseiller Femme: Voici vos 200 francs.
Conseiller Femme: Il vous reste 400 francs.
Conseiller Mari: Il vous reste 400 francs.
Conseiller Mari: Voici vos 300 francs.
Conseiller Femme: Voici vos 300 francs.
Conseiller Femme: Vous etes fauches!
Conseiller Mari: Vous etes fauches! ...
Conclusion:
le mari a retiré 600 francs du compte commun,
la femme a retiré 600 francs du compte commun,
qui ne contenait que 1000 francs au départ! La banque ne va pas être contente...
L'explication est simple et nous entraîne à faire un peu de sémantique.
L'exécution de plusieurs threads se fait en exécutant une action insécable
(``atomique'') de l'un des threads, puis d'un autre ou d'éventuellement du même
etc.
Tous les ``mélanges'' possibles sont permis
C'est ce que l'on appelle la sémantique par entrelacements; on en représente une portion ci-dessous:
Donnons une idée de la façon de donner une sémantique à un fragment
du langage JAVA (et en supposant les lectures et écritures atomiques).
Nous allons prendre comme langage un langage simple qui comprend comme constructions
(étant donné une syntaxe pour les CONSTANTEs entières et un
ensemble fini de VARIABLEs également entières):
| EXPR |
::= |
CONSTANTE |
| |
VARIABLE |
| |
| |
EXPR+EXPR |
| |
EXPR*EXPR |
| |
| |
EXPR/EXPR |
| |
EXPR-EXPR |
| TEST |
::= |
EXPR==EXPR |
| |
EXPR < EXPR |
| |
| |
EXPR > EXPR |
| |
TEST && TEST |
| |
| |
TEST | | TEST |
| |
! TEST |
| INSTR |
::= |
VARIABLE=EXPR |
| BLOCK |
::= |
e |
| |
INSTR;BLOCK |
| |
| |
if TEST |
| |
|
then BLOCK |
| |
|
else BLOCK ;BLOCK |
| |
| |
while TEST |
| |
|
BLOCK ; |
| |
|
BLOCK |
Appelons L le langage engendré par la grammaire plus haut.
On définit la sémantique d'un BLOCK inductivement sur la syntaxe,
en lui associant ce que l'on appelle un système de transitions. Un
système de transitions est un 4-uplet (S,i,E,Tran) où,
- S est un ensemble d'états,
- i Î S est l'``état initial'',
- E est un ensemble d'étiquettes,
- Tran Í S × E × S est l'ensemble des transitions.
On note plus communément (s,t,s') Î Tran comme
s ®t s'.
En fait, on représente généralement un système de transitions
comme un graphe orienté et étiqueté, comme le suggère la représentation
graphique de la relation de transition Tran, que nous avons déjà vue.
Donnons maintenant les règles de formation du système de transition
correspondant à un BLOCK. Tout d'abord appelons environnement toute
fonction de VARIABLE vers l'ensemble des entiers relatifs. Un état
du système de transition que nous allons construire sera une paire (l,r)
où l Î L et r est un environnement. Intuitivement, l est le programme
qu'il reste à exécuter et r est l'état courant de la machine, c'est
à dire la valeur courante de toutes ses variables. On a alors:
(x=expr;block,r) ®x=expr (block,r[x® [ [ expr ] ](r)])
où [ [ expr ] ] (r) dénote la valeur entière
résultat de l'évaluation de l'expression expr dans l'environnement r
(on ne donne pas les règles formelles évidentes qui donnent un sens précis
à cela...).
(if t then b1 else
b2; b3,r) ®then (b1; b3,r)
si [ [ t ] ] r = vrai
sinon
(if t then b1 else
b2; b3,r)®else (b2; b3,r)
(while t b1; b2,r) ®while
(b1;while t b1; b2,r)
si [ [ t ] ] r = vrai
sinon
(while t b1; b2,r) ®while
(b2,r)
Maintenant, supposons que l'on ait un ensemble de processus P1,...,Pn
qui chacun sont écrits dans le langage L. On peut encore donner une
sémantique opérationnelle (en termes de systèmes de transition)
dite par ``entrelacements'' en posant:
- A chaque Pj on associe par [ [ . ] ] défini plus haut un
système de transition (Sj,ij,Ej,Tranj),
- On définit (S,i,E,Tran)=[ [ P1 | ... | Pn ] ] par:
- S=S1 × ... × Sn,
- i=(i1,...,in),
- E=E1 È ... È En,
| Tran= |
ì
í
î |
(s1,...,sj,...,sn) ® |
|
(s1,...,sj',...,sn)
où |
sj ® |
|
sj' Î Tranj |
ü
ý
þ |
Les exécutions ou traces ou entrelacement dans cette sémantique sont des suites
finies:
telles que si-1 ®ti si Î Tran
pour tout i entre 1 et n.
On voit dans un des entrelacements que si les 2 threads tMari et tFemme sont exécutés de telle
façon que
dans retirer, chaque étape soit faite en même temps, alors
le test pourra être satisfait par les deux threads en même temps,
qui donc retireront en même temps de l'argent.
4.2 Une solution: synchronized
Une solution est de
rendre ``atomique'' le fait de retirer de l'argent,
Cela se fait en JAVA en déclarant ``synchronisée'' la méthode retirer
de la classe Compte:
public synchronized boolean retirer(int somme)
Maintenant l'exécution typique paraît meilleure:
% java Banque
Conseiller Mari: Voici vos 100 francs.
Conseiller Mari: Il vous reste 800 francs.
Conseiller Femme: Voici vos 100 francs.
Conseiller Femme: Il vous reste 800 francs.
Conseiller Mari: Voici vos 200 francs.
Conseiller Mari: Il vous reste 400 francs.
Conseiller Femme: Voici vos 200 francs.
Conseiller Femme: Il vous reste 400 francs.
Conseiller Femme: Il vous reste 100 francs.
Conseiller Mari: Voici vos 300 francs.
Conseiller Mari: Il vous reste 100 francs.
Conseiller Femme: Il vous reste 100 francs.
Conseiller Mari: Il vous reste 100 francs...
Le résultat est maintenant que
le mari a tiré 600 francs,
la femme a tiré 300 francs,
et il reste bien 100 francs dans le compte commun, ouf!
Remarquez que synchronized peut aussi s'utiliser sur une morceau de
code: étant donne
un objet obj:
synchronized(obj) {
BLOCK }
permet d'exécuter BLOCK en exclusion mutuelle.
4.3 Moniteurs
Chaque objet fournit un verrou, mais aussi un mécanisme de mise en attente
(forme primitive de communication inter-threads; similaire aux variables de conditions
ou aux moniteurs [Hoa74]).
void wait() attend l'arrivée d'une condition sur l'objet sur lequel
il s'applique (en général this). Il doit être
appelé depuis l'intérieur d'une méthode ou d'un bloc synchronized
(il y a aussi une version avec timeout).
void notify() notifie un thread en attente d'une condition, de
l'arrivée de celle-ci. De même, cette méthode doit être appelée depuis
une méthode déclarée synchronized.
Enfin, void notify_all() fait la
même chose mais pour tous les threads en attente
sur l'objet.
4.4 Sémaphores
4.4.1 Sémaphores binaires
public class Semaphore {
int n;
String name;
public Semaphore(int max, String S) {
n = max;
name = S;
}
public synchronized void P() {
if (n == 0) {
try {
wait();
} catch(InterruptedException ex) {};
}
n--;
System.out.println("P("+name+")");
}
public synchronized void V() {
n++;
System.out.println("V("+name+")");
notify();
}
}
Figure 4.2:
Cela permet de réaliser l'exclusion mutuelle, donc l'accès par
des processus à des sections critiques, comme on le montre à la
figure 4.3.
public class essaiPV extends Thread {
static int x = 3;
Semaphore u;
public essaiPV(Semaphore s) {
u = s;
}
public void run() {
int y;
// u.P();
try {
Thread.currentThread().sleep(100);
y = x;
Thread.currentThread().sleep(100);
y = y+1;
Thread.currentThread().sleep(100);
x = y;
Thread.currentThread().sleep(100);
} catch (InterruptedException e) {};
System.out.println(Thread.currentThread().
getName()+": x="+x);
// u.V();
}
public static void main(String[] args) {
Semaphore X = new Semaphore(1,"X");
new essaiPV(X).start();
new essaiPV(X).start();
}
}
Figure 4.3:
Une exécution typique de ce programme (sans P, V) est la suivante:
% java essaiPV
Thread-2: x=4
Thread-3: x=4
Maintenant, avec P, V on a par exemple:
% java essaiPV
P(X)
Thread-2: x=4
V(X)
P(X)
Thread-3: x=5
V(X)
4.4.2 Un peu de sémantique
On va rajouter à notre langage L les primitives P(.) et
V(.). On suppose que la syntaxe pour chacun des processus est bien
formée dans le sens suivant:
La sémantique par systèmes de transitions change assez peu:
- On rajoute dans l'ensemble d'états S du système de transitions
une composante nouvelle qui est une fonction k: VARIABLE ®
{0,1}. Donc S=(S1,...,Sn,k). Cette fonction k represente
le fait de savoir si chaque variable est verrouillée par un processus ou non,
- i=(P1,...,Pn,k0) où k0 est la fonction qui donne
uniformément 1,
- E contient maintenant les nouvelles actions Px et Vx pour toutes
les variables x du programme,
- On a de nouvelles transitions dans Tran de la forme:
(b1,...,Px;bj,...,bn,k) ®Px (b1,...,bj,...,bn,k')
si k(x)=1; et alors k'(y)=k(x) pour tout y ¹ x et
k'(x)=0, et,
(b1,...,Px;bj,...,bn,k) ®Vx (b1,...,bj,...,bn,k')
avec k'(y)=k(x) pour tout y ¹ x et
k'(x)=1.
L'apparition de ces nouvelles transitions contraint en fait les entrelacements
possibles. Si on ``abstrait'' ce système de transition (et le langage de base)
à de simples suites de verrouillages et déverrouillages de variables partagées,
on peut facilement se rendre compte de ce qui ce qui peut se passer.
Un des problèmes les plus courants est d'avoir voulu trop protéger
les accès partagés et à aboutir à une situation où les
processus se bloquent mutuellement; on dit alors qu'il y a une étreinte fatale,
ou encore que le système de transition a des points morts (des états
desquels aucune transition n'est possible, mais qui ne sont pas des états finaux
autorisés: ces états finaux autorisées seraient uniquement
en général des n-uplets des états finaux de chacun des processus).
Un exemple classique est donné par le programme ``abstrait'' suivant constitué
des deux processus:
A=Pa;Pb;Va;Vb
B=Pb;Va;Vb;Va
En regardant la sémantique par entrelacements, on trouve assez vite qu'une
exécution synchrone de A et de B rencontre un point mort: en
effet dans ce cas A (respectivement B) acquiert a (respectivement
b) et attend ensuite la resource b (respectivement a).
Une image pratique (qui s'abstrait élégamment de la lourdeur
de la représentation des entrelacements) est d'utiliser une image géométrique
continue, les ``progress graphs'' (E.W.Dijkstra (1968), ou encore les ``graphes
d'avancement''.
Associons en effet à chaque processus une coordonnée dans un espace IRn
(n étant le nombre de processus).
Chaque coordonnée xi représente en quelque sorte le temps local du
ième processus. Les états du système parallèle sont donc des
point dans cet espace IRn (inclus dans un hyper-rectangle dans les bornes
en chaque coordonnées sont les bornes des temps locaux d'exécution de
chaque processus). Les traces d'exécution sont
les chemins continus et croissants dans chaque coordonnée. Dans la figure
suivante, on a représenté le graphe de processus correspondant à nos
deux processus A et B.
On constate que certains points dans le carré unité ne sont pas des états
valides du programme parallèle. Prenons un point qui a pour coordonnée
x1 un temps local compris entre Pb et Vb et pour coordonnée
x2 un temps local compris également entre Pb et Vb (mais cette fois
pour le processus B). Il ne peut être valide car dans cet état,
les deux processus auraient chacun un verrou sur le même objet b. Cela
contredit la sémantique par système de transitions vue auparavant, c'est
à dire que cela contredit la propriété d'exclusion mutuelle sur b.
On doit également interdire le rectangle horizontal, à cause de la propriété
d'exclusion mutuelle sur la variable partagée a.
On s'aperçoit maintenant que tout chemin d'exécution (partant donc du
point initial en bas à gauche du graphe d'avancement) et qui rentrerait dans
le carré marqué ``dangereux'' doit nécessairement (par sa propriété
de croissante en chaque coordonnée et par sa continuité) aboutir au point
mort, minimum des intersections des deux rectangles interdits. Cette concavité
inférieure est responsable de l'étreinte fatale entre les processus
A et B. De même on s'aperçoit que certains états, dans la
concavité supérieure de la région interdite, sont des états inatteignables
depuis l'état initial. On reviendra la-dessus et sur des critères plus
simples pour trouver si un système a des points morts à la section 4.4.4.
Sachez simplement que ces idées apparemment simples peuvent être développées
extrêmement loin!
Remarquez également que
synchronized de JAVA
ne fait jamais que P du verrou associé à une méthode
ou à un block de code, puis V de ce même verrou à la fin de ce même
code.
Une méthode M de la classe A qui est synchronized est
équivalente à P(A), corps de M, V(A).
Il y a malgré tout une subtile différence. La construction synchronized
est
purement déclarative (contrairement à notre construction de P et à donc
une portée définie statiquement, contrairement à l'utilisation de P
et V.
4.4.3 Un complément sur la JVM
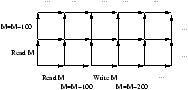
Pour bien comprendre la sémantique des communications inter-threads en JAVA,
il nous faut expliquer un peu en détail comment la JVM traite les accès
mémoire des threads.
Toutes les variables (avec leurs verrous correspondants et la liste des
threads en attente d'accès)
de tous les threads sont stockées dans la mémoire
gérée par la JVM correspondante. Bien évidemment, les variables locales
d'un thread ne peuvent pas être accédée par d'autres threads, donc on
peut imaginer que chaque thread a une mémoire locale et a accès à une
mémoire globale.
Pour des raisons d'efficacité, chaque thread a une copie locale des variables
qu'il doit utiliser, et il faut bien sûr que des mises à jour de la mémoire
principale (celle gérée par la JVM) soit effectuées, de façon cohérente.
Plusieurs actions atomiques (c'est à dire non interruptibles, ou encore
qui ne s'exécuteront qu'un à la fois sur une JVM)
peuvent être effectuées pour gérer ces copies locales
et la mémoire principales, au moins pour les types simples (int, float...).
Ces actions décomposent les accès mémoires qui sont nécessaires à l'interprétation d'une affectation JAVA:
- les actions qu'un thread peut exécuter sont:
- use transfère le contenu de la copie locale d'une variable à
la machine exécutant le thread.
- assign transfère une valeur de la machine exécutant le thread
à la copie locale d'une variable de ce même thread.
- load affecte une valeur venant de la mémoire principale (après
un read, voir plus loin) à la copie locale à un thread d'une variable.
- store transfère le contenu de la copie locale à un thread d'une
variable à la mémoire principale (qui va ainsi pouvoir faire un write,
voir plus loin).
- lock réclame un verrou associé à une variable à la mémoire
principale.
- unlock libère un verrou associé à une variable.
- les actions que la mémoire principale (la JVM) peuvent exécuter sont:
- read transfère le contenu d'une variable de la mémoire principale
vers la mémoire locale d'un thread (qui pourra ensuite faire un load).
- write affecte une valeur transmise par la mémoire locale d'un
thread (par store) d'une variable dans la mémoire principale.
Pour les types ``plus longs'' comme double et long, la spécification
permet tout à fait que load, store, read et write
soient non-atomiques. Elles peuvent par exemple être composées de deux
load atomiques de deux ``sous-variables'' int de 32 bits.
Le programmeur doit donc faire attention à synchroniser ses accès à
de tels types, s'ils sont partagés par plusieurs threads.
L'utilisation par la JVM de ces instructions élémentaires est soumise à
un certain nombre de contraintes, qui permettent de définir la sémantique
des accès aux ressources partagées de JAVA. Tout d'abord, pour un thread
donné, à tout lock correspond plus tard une opération unlock.
Ensuite, chaque opération load est associée à une opération read qui la précède; de même chaque store est associé à une
opération write qui la suit.
Pour une variable donnée et un thread donné, l'ordre dans lequel des read
sont fait par la mémoire locale (respectivement les write) est le même
que l'ordre dans lequel le thread fait les load (respectivement les
store). Attention, ceci n'est vrai que pour une variable donnée!
Pour les variables volatile, les règles sont plus contraignantes car
l'ordre est aussi respecté entre les read/load et les write/store
entre les variables. Pour les volatile on impose également que les
use suivent immédiatement les load et que les store suivent
immédiatement les assign.
Pour bien comprendre tout ça prenons deux exemples classiques, aux figures
4.5 et 4.6 respectivement. On utilise ces classes dans deux threads
de la même façon, on en donne donc le code à la figure
4.4 que dans le cas de Exemple1.
class Essai1 extends Thread {
public Essai1(Exemple1 e) {
E = e;
}
public void run() {
E.F1();
}
private Exemple1 E;
}
class Essai2 extends Thread {
public Essai2(Exemple1 e) {
E = e;
}
public void run() {
E.G1();
}
private Exemple1 E;
}
class Lance {
public static void main(String args[]) {
Exemple1 e = new Exemple1();
Essai1 T1 = new Essai1(e);
Essai2 T2 = new Essai2(e);
T1.start();
T2.start();
System.out.println("From Lance a="+e.a+" b="+e.b);
}
}
Figure 4.4:
class Exemple1 {
int a = 1;
int b = 2;
void F1() {
a = b;
}
void G1() {
b = a;
}
}
Figure 4.5:
class Exemple2 {
int a = 1;
int b = 2;
synchronized void F2() {
a = b;
}
synchronized void G2() {
b = a;
}
}
Figure 4.6:
Une exécution typique est:
> java Lance
a=2 b=2
Mais il se peut que l'on trouve également:
> java Lance
a=1 b=1
ou encore
> java Lance
a=2 b=1
En fait, pour être plus précis, les contraintes d'ordonnancement font
que les chemins possibles d'exécution sont les entrelacements des 2 traces
séquentielles
read b ® load b ® use b ® assign a ®
store a ® write a
pour le thread Essai1 et
read a ® load a ® use a ® assign b ®
store b ® write b
pour le thread Essai2. Appelons a1, b1 (respectivement a2 et b2) les copies locales des variables
a et b pour le thread Essai1 (respectivement pour le thread Essai2).
Alors on peut avoir les entrelacement suivants (modulo les commutations des
read a et read b, ce qui n'a aucune influence sur le calcul):
write a ® read a ® read b ® write b
read a ® write a ® write b ® read b
read a ® write a ® read b ® write b
Dans le premier cas l'état de la machine est la1=2, lb1=2, a=2, b=2,
la2=2 et lb2=2. Dans le deuxième on a la1=1, lb1=1, a=1, b=1,
la2=1 et lb2=1. Enfin dans le troisième, on a la1=2, lb1=2, a=2, b=1,
la1=1 et lb1=1.
Si on utilise la version synchronisée de Exemple1, qui est Exemple2
à la figure 4.6, alors on n'a plus que les deux premiers
ordonnancements qui soient possibles:
write a ® read a ® read b ® write b
read a ® write a ® write b ® read b
4.4.4 Quelques grands classiques
Exerçons un peu nos talents sur des problèmes classiques du parallélisme
(que vous aurez peut-être vu par ailleurs, par exemple en cours de système
d'exploitation).
Le premier problème est celui des
philosophes qui dînent (introduit par E. W. Dijkstra [Dij68]).
Dans le cas général, on a n philosophes assis autour d'une table ronde:
avec chacun une fourchette à sa gauche et une autre à sa droite. On n'a pas
représenté ici le sujet principal: le bol de spaghettis supposé être au
centre. Les philosophes voulant manger, doivent utiliser les 2 fourchettes en même
temps pour se servir de spaghettis. Un des premiers ``protocoles'' venant à l'esprit
est celui dans lequel chaque philosophe essaie d'attraper sa fourchette gauche,
puis droite, se sert et enfin repose la fourchette gauche puis droite. Cela donne
en JAVA le code de la figure 4.7.
public class Phil extends Thread {
Semaphore LeftFork;
Semaphore RightFork;
public Phil(Semaphore l, Semaphore r) {
LeftFork = l;
RightFork = r;
}
public void run() {
try {
Thread.currentThread().sleep(100);
LeftFork.P();
Thread.currentThread().sleep(100);
RightFork.P();
Thread.currentThread().sleep(100);
LeftFork.V();
Thread.currentThread().sleep(100);
RightFork.V();
Thread.currentThread().sleep(100);
} catch (InterruptedException e) {};
}
}
public class Dining {
public static void main(String[] args) {
Semaphore a = new Semaphore(1,"a");
Semaphore b = new Semaphore(1,"b");
Semaphore c = new Semaphore(1,"c");
Phil Phil1 = new Phil(a,b);
Phil Phil2 = new Phil(b,c);
Phil Phil3 = new Phil(c,a);
Phil1.setName("Kant");
Phil2.setName("Heidegger");
Phil3.setName("Spinoza");
Phil1.start();
Phil2.start();
Phil3.start();
} }
Figure 4.7:
Une exécution typique est:
% java Dining
Kant: P(a)
Heidegger: P(b)
Spinoza: P(c)
^C
On constate un interblocage des processus. Comment aurions nous pu nous en douter?
L'explication est simple:
quand
les trois philosophes prennent en même temps leur fourchette gauche, ils attendent
tous leur fourchettes droites...qui se trouvent être les fourchettes gauches de leur
voisin de droite.
On s'aperçoit que ce point mort est simplement dû à un cycle dans les demandes
et attributions des ressources partagées. Essayons de formaliser un peu cela.
Construisons un graphe orienté (le ``graphe de requêtes'') dont les noeuds sont
les resources et dont les arcs sont comme suit. On a un arc d'un noeud a
vers un noeud b si il existe un processus qui ayant acquis un verrou sur a
(sans l'avoir relaché) demande un verrou sur b. On étiquette alors cet
arc par le nom du processus en question. Alors on peut facilement montrer
que si le graphe de requête est acyclique alors le système constitué
par les threads considérés ne peut pas rentrer en interblocage.
En effet, en abstrayant le programme JAVA pour ne s'intéresser plus qu'aux
suites de vérrouillages et dévérrouillages, on obtient les
trois processus suivants en parallèle:
A=Pa;Pb;Va;Vb
B=Pb;Pc;Vb;Vc
C=Pc;Pa;Vc;Va
Un exemple en est donné à la figure 4.8, correspondant aux
3 philosophes, et ce graphe est bien cyclique.
On pouvait aussi s'en apercevoir sur le graphe d'avancement: le point mort est
du à l'intersection de 3 (=nombre
de processus) hyperrectangles, ou encore
la concavité ``inférieure de la figure 4.10...
mais cela nous entraîne
trop loin.
Figure 4.8: Le graphe de requêtes pour les 3 philosophes.
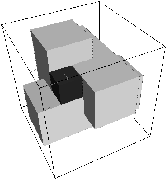
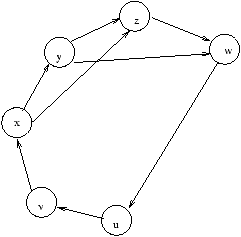
Figure 4.9: Point mort des 3 philosophes
La condition sur les graphes de requêtes est
une condition suffisante à l'absence de points morts, et non nécessaire
comme le montre l'exemple suivant (où A, B et C sont
encore 3 threads exécutés en parallèle):
A=Px;Py;Pz;Vx;Pw;Vz;Vy;Vw
B=Pu;Pv;Px;Vu;Pz;Vv;Vx;Vz
C=Py;Pw;Vy;Pu;Vw;Pv;Vu;Vv
dont on trouve le graphe de requêtes (fortement cyclique!) à la
figure 4.11. Pour avoir une idée de pourquoi cette politique d'accès
aux ressources partagées n'a pas de point mort, il faut regarder le graphe
d'avancement, représenté à la figure 4.12. La région
interdite est homéomorphe à un tore (plus ou moins sur l'antidiagonale du cube...
c'est une image bien sûr!) et le chemin passant au milieu du tore n'est jamais
stoppé par une concavité intérieure.

Figure 4.10: Graphe de requêtes pour l'exemple Lipsky/Papadimitriou.
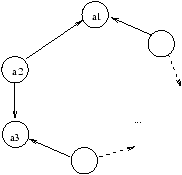
Figure 4.11:
Comment remédier au problème d'interblocage dans le cas des n philosophes?
Il faut réordonnancer
les accès aux variables partagées. Il y a beaucoup de solutions (éventuellement
avec ordonnanceur extérieur). En fait il y en a une très simple:
on numérote les philosophes, par exemple dans le sens trigonométrique autour
de la table. On impose maintenant que les philosophes
de numéro pair acquièrent la fourchette gauche d'abord, puis la droite et aussi
que
les philosophes de numéro impair acquièrent la fourchette droite d'abord,
puis la gauche ensuite. Cela donne (en terme de P et de V):
P1=Pa2;Pa1;Va2;Va1
P2=Pa2;Pa3;Va2;Va3
...
P2k=Pa2k;Pa(2k+1);Va2k;Va(2k+1)
P(2k+1)=Pa(2k+2);Pa(2k+1);Va(2k+2);Va(2k+1)
Le graphe de requêtes est décrit à la figure 4.13, on voit bien
qu'il est acyclique, donc que le système de processus ne rencontre pas de points
morts.
Figure 4.12: Le nouveau graphe de requêtes.
4.4.5 Sémaphores à compteur
On a parfois besoin d'objets qui peuvent être partagés par n processus
en même temps et pas par n+1. C'est une généralisation évidente
des sémaphores binaires (qui sont le cas n=1). Par exemple, on peut avoir
à protéger l'accès à des tampons de messages de capacité n.
On appelle les sémaphores correspondants, les sémaphores à compteur.
Il sont en fait implémentables à partir des sémaphores binaires
[Dij68], comme le fait le code de la figure 4.14.
public class essaiPVsup extends Thread {
static int x = 3;
Semaphore u;
public essaiPVsup(Semaphore s) {
u = s;
}
public void run() {
int y;
u.P();
try {
Thread.currentThread().sleep(100);
y = x;
Thread.currentThread().sleep(100);
y = y+1;
Thread.currentThread().sleep(100);
x = y;
Thread.currentThread().sleep(100);
} catch (InterruptedException e) {};
System.out.println(Thread.currentThread().
getName()+": x="+x);
u.V(); }
public static void main(String[] args) {
Semaphore X = new Semaphore(2,"X");
new essaiPVsup(X).start();
new essaiPVsup(X).start();
}
}
Figure 4.13:
Par exemple:
% java essaiPVsup
Thread-2: P(X)
Thread-3: P(X)
Thread-2: x=4
Thread-2: V(X)
Thread-3: x=4
Thread-3: V(X)
On voit bien que l'on n'a pas d'exclusion mutuelle.
Pour les tampons de capacité bornée cela peut servir comme on l'a déjà dit
(problème du type producteur consommateur) et comme on le montre par un petit
code JAVA à la figure 4.15.
public class essaiPVsup2 extends Thread {
static String[] x = {null,null};
Semaphore u;
public essaiPVsup2(Semaphore s) {
u = s;
}
public void push(String s) {
x[1] = x[0];
x[0] = s;
}
public String pop() {
String s = x[0];
x[0] = x[1];
x[1] = null;
return s; }
public void produce() {
push(Thread.currentThread().getName());
System.out.println(Thread.currentThread().
getName()+": push");
}
public void consume() {
pop();
System.out.println(Thread.currentThread().
getName()+": pop"); }
public void run() {
try {
u.P();
produce();
Thread.currentThread().sleep(100);
consume();
Thread.currentThread().sleep(100);
u.V();
} catch(InterruptedException e) {};
}
public static void main(String[] args) {
Semaphore X = new Semaphore(2,"X");
new essaiPVsup2(X).start();
new essaiPVsup2(X).start();
new essaiPVsup2(X).start();
}
}
Figure 4.14:
Dans l'exemple précédent, on a 3 processus qui partagent une file à 2 cellules
protégée (en écriture)
par un 2-sémaphore. Chaque processus essaie de produire (push)
et de consommer (pop)
des données dans cette file. Pour que la file ne perde jamais de messages, il faut
qu'elle ne puisse pas être par plus de 2 processus en même temps.
Un exemple typique d'exécution est le suivant:
% java essaiPVsup2
Thread-2: P(X)
Thread-2: push
Thread-3: P(X)
Thread-3: push
Thread-2: pop
Thread-3: pop
Thread-2: V(X)
Thread-3: V(X)
Thread-4: P(X)
Thread-4: push
Thread-4: pop
Thread-4: V(X)
4.5 Barrières de synchronisation
Un autre mécanisme de protection, ou plutôt de synchronisation qui est
courament utilisé dans les applications parallèles est ce qu'on appelle
une barrière de synchronisation. Son principe est que tout processus peut
créer une barrière de synchronisation (commune à un groupe de processus)
qui va permettre de donner un rendez-vous à exactement n processus. Ce
point de rendez-vous est déterminé par l'instruction waitForRest()
dans le code de chacun des processus. On en donne une implémentation et un
code (tiré du livre [OW00]) à la figure 4.16.
public Barrier(int nThreads) {
threads2Wait4 = nThreads;
}
public synchronized int waitForRest()
throws InterruptedException {
int threadNum = --threads2Wait4;
if (iex != null) throw iex;
if (threads2Wait4 <= 0) {
notifyAll();
return threadNum;
}
while (threads2Wait4 > 0) {
if (iex != null) throw iex;
try {
wait();
} catch(InterruptedException ex) {
iex = ex;
notifyAll();
}
}
return threadNum;
}
public synchronized void freeAll() {
iex = new InterruptedException("Barrier Released
by freeAll");
notifyAll();
}
}
Figure 4.15:
Un exemple d'utilisation typique est donné à la figure 4.17.
public class ProcessIt implements Runnable {
String[] is;
Barrier bpStart, bp1, bp2, bpEnd;
public ProcessIt(String[] sources) {
is = sources;
bpStart = new Barrier(sources.length);
bp1 = new Barrier(sources.length);
bp2 = new Barrier(sources.length);
bpEnd = new Barrier(sources.length);
for (int i=0;i<is.length; i++) {
(new Thread(this)).start(); } }
public void run() {
try {
int i = bpStart.waitForRest();
doPhaseOne(is[i]);
bp1.waitForRest();
doPhaseTwo(is[i]);
bp2.waitForRest();
doPhaseThree(is[i]);
bpEnd.waitForRest();
} catch(InterruptedException ex) {};
}
public void doPhaseOne(String ps) {
}
public void doPhaseTwo(String ps) {
}
public void doPhaseThree(String ps) {
}
static public void main(String[] args) {
ProcessIt pi = new ProcessIt(args);
}
}
Figure 4.16:
4.6 Un exemple d'ordonnanceur: séquentialisation
Considérez le problème suivant. On a une base de données distribuée
qui contient les réservations aériennes d'une grande compagnie. Les
clients réservent leurs billets au travers d'agences dans le monde entier,
qui donc n'ont aucun moyen direct de se synchroniser. Les informations sur
les réservations sont dans une mémoire d'ordinateur unique quelque part sur
la planète. Supposons que nous ayons deux clients, Bill et Tom, le premier
habitant Paris et désirant se rendre à New York (en réservant son
billet depuis l'agence de Paris), et le deuxième habitant New York et désirant
se rendre à Paris (en réservant son billet depuis l'agence de New York). Supposons
encore que ces deux clients veulent en fait exactement les mêmes vols (ce qui
est, pour des motifs temporels assez hasardeux...) et qu'il ne reste plus qu'une
place sur chacun de ces vols. Comment faire en sorte de servir ces deux clients
de façon cohérente?
Regardons le programme implémentant les requêtes de Bill et Tom de la
figure 4.19.
public class Ticket {
String nom;}
public class Requete extends Thread {
Ticket Aller;
Ticket Retour;
Semaphore u;
Semaphore v;
public Requete(Ticket t, Ticket s,
Semaphore x, Semaphore y) {
Aller = t;
Retour = s;
u = x;
v = y; }
public void run() {
try {
u.P();
Thread.currentThread().sleep(100);
if (Aller.nom == null)
Aller.nom = Thread.currentThread().
getName();
Thread.currentThread().sleep(100);
u.V();
} catch (InterruptedException e) {};
try {
v.P();
Thread.currentThread().sleep(100);
if (Retour.nom == null)
Retour.nom = Thread.currentThread().
getName();
Thread.currentThread().sleep(100);
v.V();
} catch (InterruptedException e) {};
}
}
public class Serial {
public static void main(String[] args) {
Semaphore a = new Semaphore(1,"a");
Semaphore b = new Semaphore(1,"b");
Ticket s = new Ticket();
Ticket t = new Ticket();
Requete Bill = new Requete(s,t,a,b);
Requete Tom = new Requete(t,s,b,a);
Bill.setName("Bill");
Tom.setName("Tom");
Bill.start();
Tom.start();
try {
Tom.join();
Bill.join();
} catch(InterruptedException e) {};
System.out.println("Le billet Paris->New York
est au nom de: "+s.nom);
System.out.println("Le billet New York->Paris
est au nom de: "+t.nom); } }
Figure 4.17:
Le résultat est:
% java Serial
Bill: P(a)
Tom: P(b)
Bill: V(a)
Tom: V(b)
Bill: P(b)
Tom: P(a)
Bill: V(b)
Tom: V(a)
Le billet Paris->New York est au nom de: Bill
Le billet New York->Paris est au nom de: Tom
Ce qui n'est pas très heureux: en fait aucun des deux clients ne sera content
car chacun pourra partir, mais pas revenir!
Il est facile de voir que le chemin d'exécution qui vient d'être pris correspond
à un chemin sur la diagonale du graphe d'avancement:
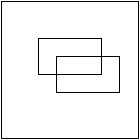
qui ``mélange'' les transactions de nos deux utilisateurs.
Il existe plusieurs protocoles permettant d'atteindre un état
plus cohérent de la base de données. Par exemple le protocole
``2-phase locking'' (voir [Abi00]) où chacun des deux clients
essaie d'abord de verrouiller tous les billets voulus, avant d'y mettre son
nom et de payer, puis de tout déverrouiller, permet cela. On dit que ce
protocole est ``séquentialisable'', c'est à dire que tous les accès à
la base de données distribuées se font comme si les deux clients étaient
dans une même agence, et surtout dans une file ordonnée...
Quand on change dans Requete, l'ordre des verrous, dans la méthode run(),
on obtient le programme de la figure 4.20 et l'exécution:
public void run() {
try {
Thread.currentThread().sleep(100);
u.P();
if (Aller.nom == null)
Aller.nom = Thread.currentThread().
getName();
u.V();
Thread.currentThread().sleep(100);
Thread.currentThread().sleep(100);
v.P();
if (Retour.nom == null)
Retour.nom = Thread.currentThread().
getName();
Thread.currentThread().sleep(100);
v.V();
} catch (InterruptedException e) {};
}
Figure 4.18:
public void run() {
try {
u.P();
v.P();
Thread.currentThread().sleep(100);
if (Aller.nom == null)
Aller.nom = Thread.currentThread().
getName();
Thread.currentThread().sleep(100);
Thread.currentThread().sleep(100);
if (Retour.nom == null)
Retour.nom = Thread.currentThread().
getName();
Thread.currentThread().sleep(100);
u.V();
v.V();
} catch (InterruptedException e) {};
}
Figure 4.19:
% java Serial2
Bill: P(a)
Bill: P(b)
Bill: V(a)
Bill: V(b)
Tom: P(b)
Tom: P(a)
Tom: V(b)
Tom: V(a)
Le billet Paris->New York est au nom de: Bill
Le billet New York->Paris est au nom de: Bill
qui ne satisfait vraiment que Bill mais qui au moins est cohérent!
Evidemment, il est aussi possible dans
ce cas qu'une exécution donne également un interblocage:
% java Serial2
Bill: P(a)
Tom: P(b)
^C
On s'aperçoit que dans le cas de la figure 4.20, le graphe d'avancement
interdit des chemins non séquentialisables, mais effectivement pas les
points morts:

Les seules obstructions sont ``au centre'': on peut déformer tout chemin sur l'un des bords.
L'interface Serializable de JAVA, assure en fait cette propriété de
séquentialisation:
- elle permet d'assurer la persistence de certains objets,
- elle est utilisée en particulier pour les entrées sorties