Lancez Visual Studio Code (VS Code par la suite), par exemple en exécutant la commande code dans le terminal, ou en cliquant sur un raccourci; la touche [Alt] fait apparaître / disparaître la barre du menu horizontale.
Dans VS Code tapez la combinaison de touches [Ctrl]+[Shift]+[P] (ou [Alt]+[V] puis cliquez sur command Palette) puis tapez «java: create» dans la barre qui apparaît et sélectionnez Create Java Project et l'option No build tools.
Une fenêtre s'ouvre et vous invite à choisir votre espace de travail.
Indiquez le nom de votre projet (TD8) dans la barre de texte.
Activer assert dans votre machine virtuelle Java
Vérifier que les assert's sont activés en exécutant le programme
TestAssert.java.
En cas de problème, suivez la procédure ci-dessous dans Visual Studio Code: tapez la combinaison de touches [Ctrl]+[,] (la second touche c'est `virgule'), indiquez vm args dans la barre de recherche.
L'item Java>Debug>settings: Vm Args apparaît avec une barre de texte dans laquelle vous devez écrire -ea (pour enable asserts).
Consignes de programmation
Nommez les classes, variables et méthodes exactement comme le demande l'énoncé.
Pour des questions relatives à la syntaxe de Java, consultez ce mémento.
Documentation
Pour obtenir la description d'une classe Java standard, consultez internet. Il suffit souvent d'effectuer une recherche en indiquant Java suivi du nom de la classe dont vous souhaitez la documentation (e.g. Java LinkedList ou Java Array).
La documentation officielle (internet) est ici : Java 11.
But
Implémenter le tri fusion en place de listes chaînées génériques, et
l'appliquer au calcul de la distribution des mots d'un texte (fonction qui
renvoie le nombre d'apparitions d'un mot dans un texte), et au calcul d'une
valeur médiane d'un ensemble de valeurs numériques.
À télécharger
Extraire le contenu du fichier TD8.zip à la racine du
projet.
Tri fusion en place
Principe
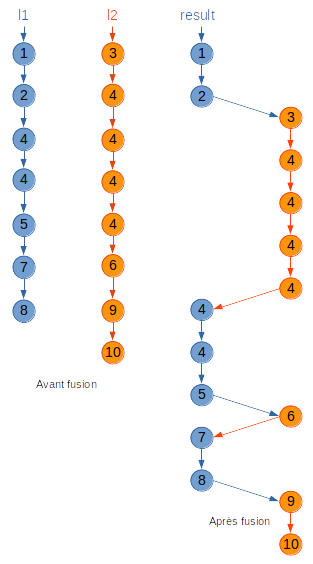
La fusion en place (merge) de deux listes chaînées ordonnées
l1 et l2 se fait sans créer ni détruire de cellules.
Comme le suggère l'illustration qui suit, l'algorithme ne fait que modifier, au
besoin, les pointeurs qui indiquent les cellules suivantes.
En particulier, les listes l1 et l2 sont détruites.
Algorithme
Les listes chaînées l1 et l2 sont deux « réserves »
dont on « prend » les éléments pour les « mettre » dans une liste auxiliaire
result (c'est-à-dire un pointeur vers la tête de la liste qu'il faudra renvoyer). L'algorithme est donc le suivant :
Initialisation :
Si l'une des « réserves » est vide on renvoie l'autre,
sinon, on initialise une liste chaînée result dans
laquelle on « met »
le plus petit des éléments l1.element et l2.element. On crée
aussi une variable last qui, au début de chaque itération, doit
pointer vers le dernier maillon de la
liste result.
Itération :
Tant qu'aucune des « réserves » n'est vide,
on « prend » le plus petit des éléments l1.element et l2.element
pour le « mettre » à la fin de la liste result,
et dès que l'une des deux « réserves » est vide, on s'arrête en renvoyant la
concaténation de la liste result et de l'autre « réserve ».
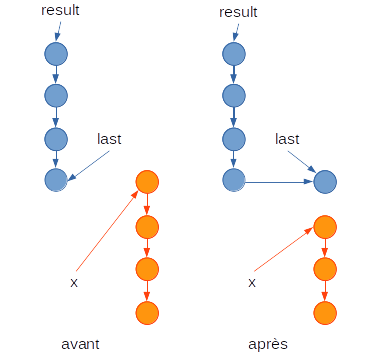
Indication : « prendre » le premier élément d'une liste x pour
le « mettre » à la fin d'une liste result dont le dernier maillon est
pointé par last se fait en modifiant quatre pointeurs, comme le
suggère la figure ci-dessous. En particulier, vous ne devez pas créer de
nouvelles cellules, c'est-à-dire ne pas utiliser d'instructions new Singly<String>.
Attention : bien que logiquement équivalents, les tests length(l) ==
0 et l == null n'ont pas la même complexité algorithmique: faites
le bon choix !
1. Listes chaînées
La classe Singly<E> implémente les listes
chaînées d'objets de la classe E.
On choisit de représenter la liste vide par la valeur null.
Chaque objet a deux champs publics :
E element, le contenu d'un maillon de la chaîne ;
Singly<E> next, le reste de la chaîne.
La classe Singly<E> offre un constructeur
Singly(E element, Singly<E> next)
ainsi que d'autres méthodes utilisées dans les tests, que vous pouvez ignorer.
Question 1 : Dans la classe Singly<E>, écrivez les méthodes
static<E> int length(Singly<E> l)
qui renvoie la longueur de son argument.
Note : pour ne pas provoquer de débordement de pile (i.e.
StackOverflowError), on écrira une boucle plutôt qu'une méthode
récursive.
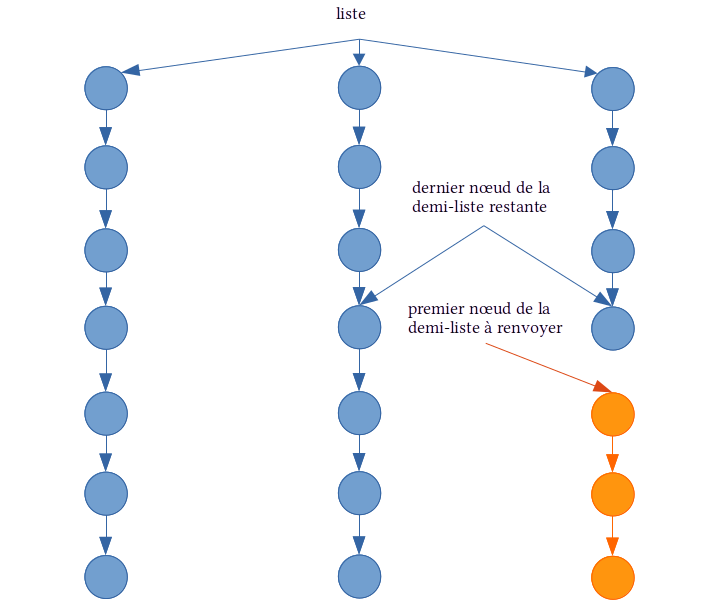
static<E> Singly<E> split(Singly<E> l)
qui coupe la liste non videl en deux moitiés égales et renvoie la
seconde moitié.
En particulier, la taille de la liste l passée en argument est réduite de moitié.
Par convention, si la longueur de la chaîne est impaire, la première moitié contient
un élément de plus que la seconde.
La méthode split travaille en place : on parcourt la moitié de la liste
et on renvoie le
contenu du champ next de l'élément sur lequel on s'est arrêté, tout en
mettant la
valeur de ce même champ à null, ce qui a pour effet de « couper » la liste.
Là encore, on écrira
une boucle plutôt qu'une méthode récursive.
Testez votre code en exécutant le fichier Test1.java.
Déposez le fichier Singly.java :
2. Tri fusion en place de listes chaînées de chaînes de caractères
2.1 Implémentation
Nous allons maintenant implémenter le tri fusion des listes de chaînes de
caractères, autrement dit des objets de la classe
Singly<String>.
Question 2.1 : Créez une classe MergeSortString dans laquelle vous devez écrire les méthodes statiques suivantes :
static Singly<String> merge(Singly<String> l1, Singly<String> l2)
réalise la fusion de deux listes chaînées ordonnées selon l'algorithme décrit ci-dessus.
En particulier, les deux listes passées en argument sont détruites.
On rappelle que les chaînes de caractères doivent être comparées au moyen de la
méthode compareTo.
Pour ne pas provoquer de débordement de pile (i.e. StackOverflowError), on écrira
une boucle plutôt qu'une méthode récursive.
static Singly<String> sort(Singly<String> l)
effectue le tri fusion en place de la liste passée en argument. Cette
dernière est donc détruite. Cette fois, on peut sans problème écrire une
méthode récursive, car la taille de la liste est divisée par deux à chaque
fois.
Notez que cette classe ne contient que des méthodes statiques et aucun
champs.
Exécutez le fichier Test21.java qui teste les méthodes merge
et sort.
Déposez le fichier MergeSortString.java :
2.2 Application : nombres d'apparitions des mots dans un texte
Question 2.2 :
Créez une classe Occurrence dont chaque objet possède les champs :
String word
int count
puis écrire dans cette class la méthode
static Singly<Occurrence> count(Singly<String> l)
qui renvoie la liste des mots présents dans une liste avec leur multiplicité.
On commencera par trier la liste passée en argument, afin que les mots
identiques se retrouvent consécutifs.
Aucun ordre n'est spécifié concernant la liste renvoyée.
Testez votre code en exécutant le fichier Test22.java.
Déposez le fichier Occurrence.java :
3. Tri fusion en place de listes chaînées quelconques
On peut trier les éléments d'une liste dès lors qu'ils
sont totalement ordonnés, autrement dit dès que leur classe implémente
l'interface Comparable.
3.1 Implémentation générique
Question 3.1 : Créez une classe MergeSort et adaptez le code de la classe MergeSortString pour écrire les méthodes suivantes dans la classe MergeSort :
Exécutez le programme contenu dans le fichier Test31.java pour tester
les méthodes génériques merge et sort.
Déposez le fichier MergeSort.java :
3.2 Application : les mots les plus fréquents
Question 3.2 : À l'aide de la méthode génériquesort (qui trie les éléments d'une liste dans l'ordre croissant) écrivez les méthodes suivantes dans la classe
Occurrence :
static Singly<Occurrence> sortedCount(Singly<String> l) qui renvoie la liste des mots présents
dans le texte avec leur multiplicité
de sorte que les mots les plus fréquents
(c'est-à-dire ceux de plus grande multiplicité) soient en
début de liste. En outre, à multiplicité égale, on veut que les mots apparaissent
dans l'ordre lexicographique.
Pour cela il faut compléter, dans la classe Occurrence, la méthode
public int compareTo(Occurrence that) qui renvoie une valeur strictement
négative (resp. positive) lorsque this est strictement plus
« petit » (resp. « grand »)
que that, et zéro uniquement lorsque this et that
sont égaux. Il faut ici interpréter « petit/grand » en fonction de l'ordre dans
lequel on veut que les occurrences soient rangées dans la liste.
NB : l'entête class Occurrence implements
Comparable<Occurrence> indique au compilateur que les
objets de la classe Occurrence sont ordonnés.
Testez votre code en exécutant le programme contenu dans le fichier
Test32.java. L'exécution du test nécessite quelques secondes.
Déposez le fichier modifié Occurrence.java :
3.3 Application : valeur médiane d'une liste de flottants
On se propose d'appliquer maintenant notre tri générique dans un
contexte différent.
Un flottant m est une valeur médiane d'une liste de flottants
lorsque :
la moitié (au moins) des éléments de la liste est supérieure ou égale à m et
la moitié (au moins) des éléments de la liste est inférieure ou égale à m.
Question 3.3 : Créez la classe Median dans laquelle vous devez écrire la méthode
static Pair<Double> median (Singly<Double> data)
qui renvoie l'intervalle des médianes possibles sous la forme d'une paire.
Si la liste est vide, la méthode renvoie la paire dont les deux composantes
sont égales à la valeur spéciale Double.NaN (un acronyme pour «Not a
Number»).
Testez votre code en exécutant le programme contenu dans le fichier
Test33.java.