


Chapter 2 Introduction au parallélisme
Ce chapitre est bien sûr loin d'être exhaustif. On n'y parle pratiquement
pas de micro-parallélisme, c'est à dire du parallélisme au niveau
des microprocesseurs. En effet la plupart des microprocesseurs modernes
sont à eux tous seuls de véritables machines parallèles. Par exemple
il n'est pas rare (par exemple Pentium) d'avoir plusieurs unités de
calcul arithmétique (dans le cas du Pentium, d'unités de calcul
flottant, ou dans le cas des processeurs MIPS, plusieurs
additionneurs, multiplicateurs etc.)
pouvant fonctionner en parallèle. On parle un peu plus
loin du calcul en pipeline qui est courant dans ce genre d'architectures.
A l'autre bout du spectre, on ne parle que très des projets les plus
en vogue à l'heure actuelle, c'est à dire des immenses réseaux
d'ordinateurs hétérogènes distribués à l'echelle d'internet.
On pourra se reporter aux divers projets de ``metacomputing'',
voir par exemple http://www.metacomputing.org/
et au projet ``GRID'', voir par exemple
http://www.gridforum.org/.
2.1 Une classification des machines parallèles
Une machine parallèle est essentiellement un ensemble de processeurs
qui coopèrent et communiquent.
Historiquement, les premières machines parallèles sont
des réseaux d'ordinateurs, et des machines
vectorielles et faiblement parallèles (années 70 - IBM 360-90 vectoriel, IRIS 80 triprocesseurs, CRAY 1 vectoriel...).
On distingue classiquement quatre types principaux de parallélisme
(Taxonomie de Tanenbaum):
SISD, SIMD, MISD et MIMD. Même si de nos jours cette
classification peut paraître un peu artificielle (le moindre micro-processeur
courant inclut lui-même plusieurs formes de micro-parallélisme).
Cette classification est basée sur les notions de flot de contrôle (deux
premières lettres, I voulant dire ``Instruction'') et flot de
données (deux dernières lettres, D voulant dire ``Data'').
2.1.1 Machine SISD
Une machine SISD (Single Instruction Single
Data) est ce que l'on appelle d'habitude une
machine de Von Neuman. Une seule instruction est exécutée à un moment
donné et une seule donnée (simple, non-structurée) est traitée à
un moment donné.
Le code suivant,
int A[100];
...
for (i=1;100>i;i++)
A[i]=A[i]+A[i+1];
s'exécute sur une machine séquentielle en faisant les additions
A[1]+A[2], A[2]+ A[3], etc., A[99]+A[100] à la suite
les unes des autres.
2.1.2 Machine SIMD
Une machine SIMD (Single Instruction Multiple
Data) est une machine qui exécute à tout instant une seule instruction,
mais qui agit en parallèle sur plusieurs données, on parle en général
de ``parallélisme de données''. Les machines SIMD
peuvent être de plusieurs types:
- (1) Parallèle
- (2) Systolique
Les machines systoliques sont des machines SIMD particulières dans lesquelles
le calcul se déplace sur une topologie de processeurs, comme un front d'onde,
et acquière des données locales différentes à chaque déplacement
du front d'onde (comportant plusieurs processeurs, mais pas tous en général
comme dans le cas (1)).
En général dans les deux cas, l'exécution en parallèle de la même instruction
se fait en même temps sur des processeurs différents (parallélisme
de donnée synchrone).
Examinons par exemple le code suivant (cas (1))
écrit en
CM-Fortran sur la Connection Machine-5 avec 32 processeurs,
INTEGER I,A(32,1000)
CMF$ LAYOUT A(:NEWS,:SERIAL)
...
FORALL (I=1:32,J=1:1000)
$ A(I:I,J:J)=A(I:I,J:J)+A(I:I,(J+1):(J+1))
Chaque processeur i, 1 £ i £ 32
a en sa mémoire locale une tranche du tableau
A: A(i,1), A(i,2), ..., A(i,1000). Il n'y a pas d'interférence
dans le calcul de la boucle entre les différentes tranches: tous les
processeurs exécutent la même boucle sur leur propre tranche en même
temps (cf. figure 2.1).
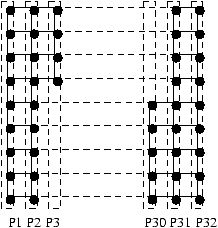
Figure 2.1: Répartion d'un tableau sur les processeurs d'une machine SIMD typique
2.1.3 Machine MISD
Une machine MISD (Multiple Instruction Single
Data) peut exécuter plusieurs instructions en même temps
sur la même donnée. Cela peut paraître paradoxal mais cela
recouvre en fait un type très ordinaire de micro-parallélisme dans
les micro-processeurs modernes: les processeurs vectoriels et
les architectures pipelines.
Un exemple de ``pipelinage'' d'une addition vectorielle est le suivant.
Considérons le code:
FOR i:=1 to n DO
R(a+b*i):=A(a'+b'*i)+B(a''+b''*i);
A, B et R sont placés dans des registres vectoriels
qui se remplissent au fur et à mesure du calcul,
| Temps |
A |
( |
i |
) |
B |
( |
i |
) |
R |
( |
i |
) |
| 1 |
1 |
. |
. |
. |
1 |
. |
. |
. |
. |
. |
. |
. |
| 2 |
2 |
1 |
. |
. |
2 |
1 |
. |
. |
. |
. |
. |
. |
| 3 |
3 |
2 |
1 |
. |
3 |
2 |
1 |
. |
. |
. |
. |
. |
| 4 |
4 |
3 |
2 |
1 |
4 |
3 |
2 |
1 |
. |
. |
. |
. |
| 5 |
5 |
4 |
3 |
2 |
5 |
4 |
3 |
2 |
1 |
. |
. |
. |
| 6 |
6 |
5 |
4 |
3 |
6 |
5 |
4 |
3 |
2 |
1 |
. |
. |
| etc. |
En ce sens, quand le pipeline est rempli, plusieurs instructions sont
exécutées sur la même donnée.
2.1.4 Machine MIMD
Le cas des machines MIMD (Multiple Instruction Multiple
Data) est le plus intuitif et est celui qui va nous intéresser le
plus dans ce cours. On a plusieurs types d'architecture possibles:
- (1) Mémoire partagée (Sequent etc.)
- (2) Mémoire locale + réseau de communication (Transputer, Connection
Machine, local, par réseau d'interconnexion) - Système réparti
C'est le cas (1) que l'on va voir plus particulièrement avec JAVA. On
pourra également simuler le cas (2). Pour le cas (2) (en PVM et
MPI) et en particulier
des applications au calcul scientifique, on pourra se reporter par
exemple au cours [GNS00].
Mémoire Partagée:
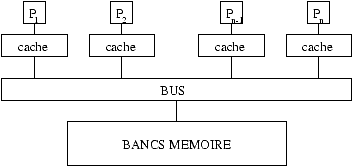
Figure 2.2: Architecture simplifiée d'une machine à mémoire partagée
Une machine MIMD à mémoire partagée
est principalement constituée de
processeurs avec des horloges indépendantes, donc évoluant de façon asynchrone,
et communicant en écrivant et lisant des valeurs dans une seule et même
mémoire (la mémoire partagée). Une difficulté supplémentaire, que
l'on ne décrira pas plus ici,
est que chaque processeur a en général au moins un cache
de données (voir figure 2.2),
tous ces caches devant avoir des informations cohérentes aux moments
cruciaux.
La synchronisation des exécutions des processeurs (ou processus, qui en
est une ``abstraction logique'') est nécessaire dans certains
cas. Si elle n'était pas faite, il y aurait un risque d'incohérence des
données.
Partant de x=0, exécutons x:=x+x en parallèle avec x:=1.
On a alors essentiellement
trois exécutions possibles (en supposant chacune des affectations
compilées en instructions élémentaires insécables, ou ``atomiques'', comme
suit):
| LOAD x,R1 |
WRITE x,1 |
LOAD x,R1 |
| LOAD x,R2 |
LOAD x,R1 |
WRITE x,1 |
| WRITE x,1 |
LOAD x,R2 |
LOAD x,R2 |
| WRITE x,R1+R2 |
WRITE x,R1+R2 |
WRITE x,R1+R2 |
| Résultat x=0 |
Résultat x=2 |
Résultat x=1
|
Cela n'est évidemment pas très satisfaisant; il faut rajouter des synchronisations
pour choisir tel ou tel comportement. Cela est en particulier traité
à la section 4.6.
La synchronisation peut se faire par différents mécanismes:
- Barrières de synchronisation,
- Sémaphores : deux opérations P et V.
- Verrou (mutex lock) : sémaphore binaire qui sert à
protéger une section critique.
- Moniteurs : construction de haut niveau, verrou implicite.
- etc.
Les opérations P et V sur les sémaphores sont parmi les plus classiques
et élémentaires (on les verra par la suite en long, en large et en travers,
en particulier à la section 4.4).
On peut considérer qu'à chaque variable partagée x dans
la mémoire est associé un ``verrou'' (du même nom) indiquant
si un processus est en train de la manipuler, et ainsi en en interdisant l'accès
pendant ce temps. L'opération Px exécutée par un processus verrouille
ainsi son accès exclusif à x. L'opération Vx ouvre le verrou et
permet à d'autres processus de manipuler x à leur tour.
La encore des erreurs sont possibles, en voulant trop synchroniser par exemple.
Il peut y avoir des cas d'interblocage (deadlock, livelock) en particulier.
Supposons qu'un processus T1 ait besoin (pour effectuer un calcul
donné) de verrouiller puis déverrouiller
deux variables x et y dans l'ordre suivant:
P x puis P y puis Vx puis Vy alors qu'un autre processus, en parallèle,
désire faire la séquence P y, P x puis V y et enfin Vx. En fait
les deux processus peuvent s'interbloquer l'un l'autre si T1 acquiert
x (respectivement T2 acquiert y) puis attend y (respectivement x).
Tout cela sera encore traité à la section 4.4.2.
Machine distribuée
En général, l'emploi d'autres mécanismes de communication
que la mémoire partagée
pour une machine MIMD est due au fait que les processeurs sont physiquement
trop éloignés pour qu'un partage de petites informations soit raisonnable,
par exemple, le réseau Internet permet de considérer en un certain sens,
tous les ordinateurs reliés comme étant un seul et même ordinateur
distribué, où les processeurs travaillent de façon asynchrone et
où les informations transitent par passage de message. Ce n'est en fait
pas toujours le cas, et un certain nombre de super-calculateurs travaillent par
échange de messages également.
De façon générale, la synchronisation et l'échange d'information
peuvent se faire par,
- Appel de procédure distribuée (RPC) :
- réponse synchrone
- réponse asynchrone
- Envoi/Réception de message asynchrone (tampon de taille limitée ou non); active
polling ou gestion à l'arrivée par une procédure handler.
- Envoi/Réception de message synchrone : rendez-vous.
- Mélange des deux derniers cas.
Le protocole RPC (``Remote Procedure Call'') entre machines UNIX avec
réseau Ethernet est un exemple de programmation MIMD (cf. figure 2.3).
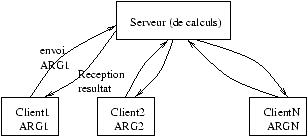
Figure 2.3: Architecture Client/Serveur (RPC)
2.1.5 Remarque
Les architectures sont plus ou moins bien adaptées à certains problèmes.
En fait, le gain de temps espéré, qui est d'au plus N (nombre de
processeurs)est rarement atteint et,
en pratique, parallélisme difficile à contrôler.
Enfin, pour revenir à notre première remarque sur la taxonomie de Tanenbaum,
il y a de plus en plus rarement une distinction tranchée entre le modèle
mémoire partagée et celui par passage de messages; dans la realité, la
situation est très hybride.
2.2 Contrôle d'une machine parallèle
Il y a deux méthodes principales,
- (1) On dispose d'un language séquentiel: le compilateur parallélise
(Fortran...),
- (2) On a une extension d'un langage séquentiel ou un langage dédié
avec des constructions parallèles explicites (Parallel C, Occam...)
On pourra se reporter à [Rob00] et [GNS00] pour
les techniques dans le cas (1).
On se concentre ici principalement sur le deuxième cas. Il faut alors
disposer de primitives (ou instructions) pour:
- La création de parallélisme,
- Itération simultanée sur tous les processeurs
(FOR parallèle de Fortran ou FORALL),
- Définition d'un ensemble de processus (COBEGIN cf. figure
2.4),
- Création de processus (FORK de Unix)
- Contrôler les tâches parallèles,
- Synchronisation (Rendez-vous d'Ada),
- Passage de messages (synchrones/asynchrones,
broadcast,...),
- Section critiques (gestion de la mémoire partagée),
- Arrêt d'une exécution parallèle (COEND, WAIT
d'Unix)
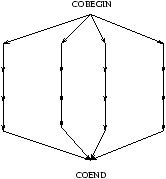
Figure 2.4: Représentation simplifiée du flot d'exécution dans
le cas d'un COBEGIN/COEND
2.3 Quelques exemples de machines parallèles
Pour réver un peu, on décrit ci-après quelques architectures
typiques de super-calculateurs. Il est également intéressant de
se reporter au chapitre traitant du routage dans le cours d'Y. Robert
[Rob00].
2.3.1 La Connection Machine-5
Elle est composée de,
- 32 à 65536 noeuds qui chacun comporte,
- un processeur Sparc (32 MHz, 22 Mips, 5 MFlops)
- 4 unités vectorielles (32 MFlops chacune) pour les opérations flottantes
- 4 bancs mémoire de 8 Mo de DRAM
- Réseau d'interconnexion en arbre gras (hypercube), entre voisins on
a: bande passante: 20 Mo/s, latence: 5 µs
- Entrées/Sorties en parallèle à un système de disques,
bande passante: 33 Mo/s,
latence: 75 ms
Plusieurs modèles (voir figure 2.5)
ont été installés en France, dont un à l'ETCA (32 noeuds,
2 processeurs de contrôle, 1 Go de RAM, 16 Go de disques, 4 GFlops
crête, mai 1993).

Figure 2.5: Une Connection-Machine 5
Elle peut fonctionner en,
- mode SIMD: CM Fortran (sous-ensemble de Fortran 90 et instructions
spécifiques d'organisation des données en parallèle),
C*
- mode MIMD: de même mais en utilisant la librairie CMMD de passage
de messages (on retrouve des ordres similaires dans PVM)
2.3.2 Cray T3E
La machine la plus puissante chez CRAY, deux types de modèles,
refroidissement à air (pas
plus de 128 processeurs)
ou par un liquide (jusqu'à 2048 processeurs). Pour les deux types de
modèles on peut avoir des configurations (voir figures 2.6
et 2.7):
- De 16 à 2048 noeuds comprenant chacun,
- un DEC Alpha EV5 (600 MFlops)
- de 64 Mo à 2 Go de mémoire vive
- Un réseau d'interconnexion en tore 3D (bande passante de 2 à
128 Go/s). Entrées sorties par un réseau en double anneau (allant dans
des sens inverses), ``GigaRing''
Performance de crête de 9.6 GFlops à 1.2 TFlops, jusqu'à 4 To de
mémoire vive.


Figure 2.6: Un T3E à plusieurs racks
Il peut être utilisé,
- langages: Fortran 90, C et C++ (compilateurs optimisants)
- mode MIMD en utilisant la ``Cray Message Passing Toolkit'' supportant
PVM, MPI (passage de messages) ou la ``Shared Memory Library'' (le CRAY
T3E est organisé logiquement en mémoire partagée même si physiquement
ce n'est pas le cas)
- mode SIMD en utilisant Fortran 90, CRAFT ou HPF
2.3.3 IBM SP2
L'IBM RISC/6000 Scalable POWERparallel System (SP) est constitué de
(voir figure 2.8):
- Noeuds avec un processeur RS/6000 soit à 120 MHz
(``thin node'' -- 480 MFlops) avec 256Mo de mémoire vive et 1,8 Go de
mémoire disque, soit à 135 MHz (``wide node'' -- 540 MFlops) avec 1 à
2 Go de mémoire vive.
- Communication par passage de messages à travers un réseau
cross-bar à deux niveaux; bande passante de 150Mo par seconde.
- Fonctionne en MIMD avec PVM ou MPI
- Fonctionne en SIMD avec HPF (High Performance Fortran)

Figure 2.7: Un IBM SP2
2.3.4 Réseaux de stations
Un réseau de stations fonctionne en mode MIMD avec une
communication par passage de messages
(typiquement gérés par PVM ou par JAVA)
sur un réseau local ou d'interconnexion.
En fait, un réseau de stations est souvent une architecture hybride dans le
sens où
il peut y avoir
combinaison sur un réseau local de stations et de machines multiprocesseurs
(elles-même gérant leur parallélisme interne par mémoire partagée
ou par bus ou réseau). JAVA et PVM peuvent également gérer ce genre d'architecture.
2.3.5 Top 500
Il est établi régulièrement une liste des 500 machines les plus puissantes,
la puissance étant mesurée par un benchmark d'algèbre linéaire et Rmax
étant la performance en Gflop/s pour le problème le plus gros programmé
sur l'ordinateur
(voir http://www.top500.org). En novembre 2001 on trouvait:
| Rang |
Constructeur |
Ordinateur |
Rmax |
| 1 |
IBM |
ASCI White (USA) |
7226 |
| 2 |
Compaq |
AlphaServer SC ES45/1 GHz (USA) |
4059 |
| 3 |
IBM |
SP Power3 375 MHz
16 way (USA) |
3052 |
| 4 |
Intel |
ASCI Red (USA) |
2379 |
| 5 |
IBM |
ASCI Blue-Pacific
SST,IBM SP 604e (USA) |
2144 |
| ... |
... |
... |
... |
| 9 |
IBM |
SP Power3 375 MHz
16 way (All) |
1293
|
| ... |
... |
... |
... |
| 56 |
IBM |
SP Power3 375 MHz (Fr) |
494 |
Pour avoir une idée des puissances requises selon les domaines d'application,
on pourra se reporter à [CS98]. En quelques mots, il faut
savoir que la prévision météorologique à deux jours demande environ
100 Mégaoctets de mémoire et 100 Mégaflops, pour 3 jours il faut compter
environ 1 Gigaoctet pour environ 10 Gigaflops. Le design d'une molécule
pharmaceutique nécessite à l'heure actuelle environ 10 Gigaoctets pour
100 Gigaflops.