


4.1 Introduction
Dans ce premier chapitre sur la modélisation ``théorique'' de la calculabilité et
de la complexité sur une machine parallèle, on fait un certain nombre d'hypothèses
simplificatrices, voire très peu réalistes.
Tout comme la complexité des algorithmes séquentiels suppose que ceux-ci
sont exécutés sur une machine conforme au modèle de Von Neumann, aussi
appelée
RAM pour Random Access Machine, nous avons besoin de définir un modèle
de machine parallèle ``théorique'',
pour pouvoir analyser le comportement asymptotique d'algorithmes
utilisant plusieurs unités de calcul à la fois.
Le modèle le plus répandu est la PRAM (Parallel Random Access Machine),
qui est composée:
-
d'une suite d'instructions à exécuter plus un pointeur sur
l'instruction courante,
- d'une suite non bornée de processeurs parallèles,
- d'une mémoire partagée par l'ensemble des processeurs.
La PRAM ne possédant qu'une seule mémoire et qu'un seul pointeur de
programme,
tous les processeurs exécutent la même opération au même moment.
Supposons que nous voulions modéliser ce qui se passe sur une machine parallèle dont
les processeurs peuvent communiquer entre eux à travers une mémoire partagée.
On va tout d'abord supposer que l'on a accès à un nombre éventuellement infini de
processeurs.
Maintenant, comment
modéliser le coût d'accès à une case mémoire? Quel est le coût d'un accès
simultané de plusieurs processeurs à la mémoire partagée? L'hypothèse que l'on
va faire est que le coût d'accès de n'importe quel nombre de processeurs à n'importe
quel sous-ensemble de la mémoire, est d'une unité. On va aussi se permettre de faire trois
types d'hypothèses sur les accès simultanés à une même case mémoire:
-
EREW (Exclusive Read Exclusive Write): seul un processeur peut lire et écrire à un moment
donné sur une case donnée de la mémoire partagée.
- CREW (Concurrent Read Exclusive Write): plusieurs processeurs peuvent lire en même temps
une même case, par contre, un seul à la fois peut y écrire.
C'est un modèle proche des machines
réelles (et de ce que l'on a vu à propos des threads JAVA).
- CRCW (Concurrent Read Concurrent Write): c'est un modèle étonnament puissant et assez
peu réaliste, mais qu'il est intéressant de considérer d'un point de vue théorique.
Plusieurs processeurs peuvent lire ou écrire en même temps sur la même case de la
mémoire partagée. Il nous reste à définir ce qui se passe lorsque plusieurs processeurs
écrivent au même moment; on fait généralement l'une des trois hypothèses suivantes:
-
mode consistant: tous les processeurs qui écrivent en même temps sur la même case
écrivent la même valeur.
- mode arbitraire: c'est la valeur du dernier processeur qui écrit qui est prise en compte.
- mode fusion: une fonction associative (définie au niveau de la mémoire), est appliquée
à toutes les écritures simultanées sur une case donnée. Ce peut être par exemple,
une fonction maximum, un ou bit à bit etc.
Les algorithmes que nous allons développer dans les sections suivantes seront déclarés être des algorithmes
EREW, CREW ou CRCW si nous pouvons les écrire de telle façon qu'ils respectent les
hypothèses de ces différents modes de fonctionnement.
4.2 Technique de saut de pointeur
Ceci est la première technique importante sur les machines PRAM. On l'illustre
dans le cas assez général où l'on souhaite calculer le résultat d'une opération
binaire associative Ä
sur un n-uplet. Soit donc (x1,...,xn) une suite
(en général de nombres). Il s'agit de calculer la suite (y1,...,yn) définie
par y1=x1 et, pour 1 £ k £ n, par
yk=yk-1 Ä xk
Pour résoudre ce problème on choisit une PRAM avec n processeurs. Remarquez ici que le
nombre de processeurs dépend du nombre de données!
L'opérateur binaire associatif que l'on utilise sera représenté par op.
Chaque valeur xi et yi est représentée par une
variable partagée x[i] et y[i], qui va être gérée par le processeur Pi.
On représente le n-uplet
(x1,...,xn) par une liste chaînée, avec la case pointée par next[i]
qui contient x[i+1] pour
i < n et next[n]=nil.
On obtient alors l'algorithme suivant:
for each processor i in parallel {
y[i] = x[i];
}
while (exists object i s.t. next[i] not nil) {
for each processor i in parallel {
if (next[i] not nil) {
y[next[i]] =_next[i] op_next[i](y[i],y[next[i]]);
next[i] =_i next[next[i]];
}
}
}
On a pris les notations (que l'on utilisera rarement, car elles sont lourdes):
-
op_j pour préciser que l'opération op s'effectue sur le processeur j.
- =_j pour préciser que l'affectation est faite par le processeur j.
Notons [i,j]=xi Ä xi+1 Ä ... Ä xj pour i < j. Les quatre étapes
nécessaires au calcul, pour n=6 sont représentées à la figure 4.1. On note
qu'à la fin, tous les next[i] valent nil.
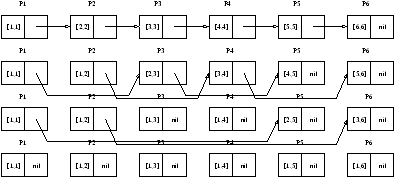
Figure 4.1: Technique du saut de pointeur.
Le principe de l'algorithme est simple: à chaque étape de la boucle, les listes courantes sont
dédoublées en des listes des objets en position paire, et des objets en position impaire.
C'est le même principe que le ``diviser pour régner'' classique en algorithmique séquentielle.
Remarquez que si on avait écrit
y[i] =_i op_i(y[i],y[next[i]]);
à la place de
y[next[i]] =_next[i] op_next[i](y[i],y[next[i]]);
on aurait obtenu l'ensemble des préfixes dans l'ordre inverse, c'est-à-dire que P1 aurait
contenu le produit [1,6], P2 [1,5], jusqu'à P6 qui aurait calculé [6,6].
Il y a tout de même une petite difficulté: nous avons parlé d'étapes, et il est vrai
que la seule exécution qui nous intéresse, et qui est correcte, est celle où chacun des
processeurs est d'une certaine façon synchronisé: chacun en est au même déroulement
de boucle à tout moment. C'est la sémantique du for parallèle
que nous choisirons pour la suite. De plus une boucle parallèle du style:
for each processor i in parallel
A[i] = B[i];
a en fait exactement la même sémantique que le code suivant:
for each processor i in parallel
temp[i] = B[i];
for each processor i in parallel
A[i] = temp[i];
dans lequel on commence par effectuer les lectures en parallèle, puis, dans un
deuxième temps, les écritures parallèles.
Il y a clairement ë log(n) û itérations dans l'algorithme du saut de pointeur, pour le
calcul du produit d'une suite de nombre, et on obtient facilement un algorithme
CREW en temps logarithmique. Il se trouve que l'on obtient la même complexité dans le
cas EREW, cela en transformant simplement les affectations dans la boucle, en passant par
un tableau temporaire:
d[i] = d[i]+d[next[i]];
devient:
temp[i] = d[next[i]];
d[i] = d[i]+temp[i];
Supposons que l'opération associative dans notre cas soit la somme. Voici un exemple d'implémentation
de cette technique de saut de pointeurs avec des threads JAVA.
On dispose d'un tableau t contenant n éléments de type int. Ici on s'est contenté
de donner le code pour le cas n=8.
On souhaite écrire un programme calculant les sommes partielles des éléments de t.
Pour cela, on crée n threads, le thread p étant chargé de calculer
åi=0i=p-1t[i].
public class SommePartielle extends Thread {
int pos,i;
int t[][];
SommePartielle(int position,int tab[][]) {
pos = position;
t=tab;
}
public void run() {
int i,j;
for (i=1;i<=3;i++) {
j = pos-Math.pow(2,i-1);
if (j>=0) {
while (t[j][i-1]==0) {} ; // attendre que le resultat soit pret
t[pos][i] = t[pos][i-1]+t[j][i-1] ;
} else {
t[pos][i] = t[pos][i-1] ;
};
};
}
}
L'idée est que le résultat de chacune des 3=log2(n) étapes, disons l'étape i, du saut de pointeur se trouve
en t[proc][i] (proc étant le numéro du processeur concerné, entre 0 et 8).
Au départ, on initialise (par l'appel au constructeur SommePartielle) les valeurs que voient
chaque processeur: t[proc][0]. Le code ci-dessous initialise le tableau d'origine de façon aléatoire,
puis appelle le calcul parallèle de la réduction par saut de pointeur:
import java.util.* ;
public class Exo3 {
public static void main(String[] args) {
int[][] tableau = new int[8][4];
int i,j;
Random r = new Random();
for (i=0;i<8;i++) {
tableau[i][0] = r.nextInt(8)+1 ;
for (j=1;j<4;j++) {
tableau[i][j]=0;
};
};
for (i=0;i<8;i++) {
new SommePartielle(i,tableau).start() ;
};
for (i=0;i<8;i++) {
while (tableau[i][3]==0) {} ;
};
for (i=0;i<4;i++) {
System.out.print("\n");
for (j=0;j<8;j++) {
System.out.print(tableau[j][i]+" ");
};
};
System.out.print("\n");
}
}
4.3 Circuit Eulerien
On souhaite calculer à l'aide d'une machine PRAM EREW la profondeur de tous les
noeuds d'un arbre binaire. C'est l'extension naturelle du problème de la section précédente,
pour la fonction ``profondeur'', sur une structure de données plus complexe que les listes.
On suppose qu'un arbre binaire est représenté par un type
abstrait arbre_binaire contenant les champs suivants :
-
int numero : numéro unique associé à chaque noeud,
- int profondeur : valeur à calculer,
- arbre_binaire pere : père du noeud courant de l'arbre,
- arbre_binaire fg,fd : fils gauche et droit du noeud courant dans l'arbre.
Un algorithme séquentiel effectuerait un parcours en largeur d'abord,
et la complexité dans le pire cas serait de O(n) où
n est le nombre de noeuds de l'arbre.
Une première façon de paralléliser cet algorithme consiste à propager une ``vague''
de la racine de l'arbre vers ses feuilles. Cette vague atteint tous les noeuds de même
profondeur au même moment et leur affecte la valeur d'un compteur correspondant à la profondeur actuelle.
Un pseudo-code serait (où le forall indique une boucle for effectuée en parallèle):
actif[0] = true;
continue = true;
p = 0; /* p est la profondeur courante */
forall j in [1,n-1]
actif[j] = false;
while (continue == true)
forall j in [0,n-1] such that (actif[j] == true) {
continue = false;
prof[j] = p;
actif[j] = false;
if (fg[j] != nil) {
actif[fg[j]] = true;
continue = true;
p++; }
if (fd[j] != nil) {
actif[fd[j]] = true;
continue = true;
p++; }
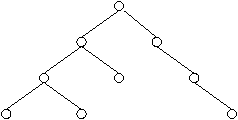
Figure 4.2:
Un arbre binaire assez quelconque.
La complexité de ce premier algorithme est de O(log(n)) pour les arbres équilibrés,
O(n) dans le cas le pire (arbres
``déséquilibrés'') sur une PRAM CRCW.
Nous souhaitons maintenant écrire un second algorithme dont la complexité est meilleure que la précédente.
Tout d'abord, nous rappelons qu'un circuit Eulerien d'un graphe orienté G est un circuit passant une et une seule fois
par chaque arc de G. Les sommets peuvent être visités plusieurs fois lors du parcours.
Un graphe orienté G possède un circuit Eulerien si et seulement si le degré entrant de chaque noeud v
est égal à son degré sortant.
Il est possible d'associer un cycle Eulerien à tout arbre binaire dans lequel on remplace les
arêtes par deux arcs orientés de sens opposés,
car alors
le degré entrant est alors trivialement égal au degré sortant.
Remarquons que dans un arbre binaire, le degré (total) d'un noeud est d'au plus 3. Dans un circuit eulérien, tout arc
est pris une unique fois, donc on passe au plus 3 fois par un noeud.
Nous associons maintenant 3 processeurs d'une machine PRAM, Ai, Bi et Ci,
à chaque noeud i de l'arbre. On suppose que chacun des 3n processeurs possède deux variables
successeur et poids. Les poids sont des valeurs entières égales à -1 (pour Ci), 0
(pour Bi) et 1 (pour Ai).
Il est alors possible de définir un chemin reliant tous les processeurs et tel que la somme des
poids rencontrés sur un chemin allant de la source à un noeud Ci soit égale à la profondeur
du noeud i dans l'arbre initial.
En effet, il est clair que la visite d'un sous-arbre à partir d'un noeud se fait par un chemin de poids nul (car
on repasse à chaque fois par un -1, 0 et un 1, de somme nulle). Donc le poids d'un noeud est égal à la
somme des poids associés aux processeurs Ai, c'est-à-dire à la profondeur.
Pour obtenir un algorithme pour PRAM EREW permettant de calculer le chemin précédent, il s'agit d'initialiser
les champs successeur et poids de chaque processeur à l'aide de l'arbre initial.
On suppose pour simplifier que les noeuds sont identifiés à leur numéro et que
pere, fg et fd sont des fonctions qui à un numéro associent un numéro.
On suppose également que les processeurs Ai ont pour numéro 3i, les Bi ont pour numéro 3i+1, et les
Ci ont pour numéro 3i+2. Alors on définit:
-
successeur[3i] = 3fg[i] si fg[i] est différent de null et
successeur[3i] = 3i+1 sinon.
- successeur[3i+1] = 3fd[i] si fd[i] est différent de null et
successeur[3i+1] = 3i+2 sinon.
- successeur[3i+2] = 3pere[i]+2
Tout ceci se fait en temps constant.
A partir de l'initialisation des champs effectuée comme précédemment, il suffit d'utiliser la
technique de saut de pointeur vue à la section 4.2
sur le parcours des 3n processus Ai, Bi et Ci.
Tout ceci se fait donc en O(log(n)).
4.4 Théorèmes de simulation
Dans ce paragraphe, nous discutons de la puissance comparée des machines CRCW, CREW et EREW.
Tout d'abord, remarquons que l'on peut trivialiser certains calculs sur une CRCW. Supposons
que l'on souhaite calculer le maximum d'un tableau A à n éléments sur une
machine CRCW à n2 processeurs. En fait chaque processeur va contenir un couple de
valeurs A[i], A[j] plus d'autres variables intermédiaires.
Le programme est alors le suivant:
for each i from 1 to n in parallel
m[i] = TRUE;
for each i, j from 1 to n in parallel
if (A[i] < A[j])
m[i] = FALSE;
for each i from 1 to n in parallel
if (m[i] == TRUE)
max = A[i];
La PRAM considérée fonctionne en mode CRCW en mode consistant, car tous les processeurs qui
peuvent écrire en même temps sur une case (en l'occurence un m[i]) ne peuvent
écrire que FALSE.
On constate que l'on arrive ainsi à calculer le maximum en temps constant sur une CRCW, alors
qu'en fait, on n'avait pu faire mieux que ë log(n) û dans le cas d'une CREW, et
même d'une EREW.
Pour séparer une CREW d'une EREW, il existe un problème simple. Supposons que l'on dispose
d'un n-uplet (e1,...,en) de nombres tous distincts, et que l'on cherche si un
nombre donné e est l'un de ces ei. Sur une machine CREW, on a un programme qui résout
ce problème en temps constant, en effectuant chaque comparaison avec un ei sur des processeurs distincts (donc
n processeurs en tout):
res = FALSE;
for each i in parallel {
if (e == e[i])
res = TRUE;
Comme tous les ei sont distincts, il ne peut y avoir qu'un processeur qui essaie d'écrire sur
res, par contre, on utilise ici bien évidemment le fait que tous les processeurs peuvent
lire e en même temps.
Sur une PRAM EREW, il faut dupliquer la valeur de e sur tous les processeurs. Ceci ne peut se
faire en un temps meilleur que log(n), par dichotomie. Ceci vaut également pour l'écriture concurrente.
On va maintenant voir que ce facteur
est un résultat général.
Théorème
Tout algorithme sur une machine PRAM CRCW (en mode consistant)
à p processeurs ne peut pas être plus de
O(log(p)) fois plus rapide que le meilleur algorithme PRAM EREW à p processeurs pour le
même problème.
.3cm
Soit en effet un un algorithme CRCW à p processeurs. On va simuler chaque pas de cet
algorithme en O(log(p)) pas
d'un algorithme EREW. On va pour ce faire utiliser un tableau auxiliaire A de p éléments, qui
va nous permettre de réorganiser les accès mémoire. Quand un processeur Pi de l'algorithme
CRCW écrit une donnée xi à l'adresse li en mémoire, le processeur Pi de
l'algorithme EREW effectue l'écriture exclusive A[i]=(li,xi). On trie alors le
tableau A suivant la première coordonnée en temps O(log(p)) (voir algorithme de Cole,
[RL03]). Une fois A trié, chaque processeur Pi de l'algorithme EREW inspecte les deux
cases adjacentes A[i]=(lj,xj) et A[i-1]=(lk,xk), où 0 £ j, k £ p-1. Si
lj ¹ lk ou si i=0, le processeur Pi écrit la valeur xj à l'adresse lj, sinon
il ne fait rien. Comme A est trié suivant la première coordonnée, l'écriture est bien
exclusive.
On a représenté ce codage, à travers les opérations effectuées sur le tableau A, à
la figure 4.3.
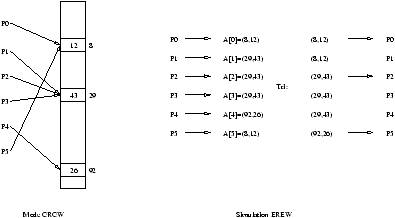
Figure 4.3: Codage d'un algorithme CRCW sur une PRAM EREW
Voici maintenant un autre théorème de simulation, qui a des applications plus surprenantes
que l'on pourrait croire au premier abord:
Théorème (Brent)
Soit A un algorithme comportant un nombre total de m opérations et qui s'exécute en temps t sur
une PRAM (avec un nombre de processeurs quelconque). Alors on peut simuler A en temps O(m/p+t
) sur une PRAM de même type avec p processeurs.
.3cm
En effet, à l'étape i, A effectue m(i) opérations, avec åi=1n m(i)=m. On
simule l'étape i avec p processeurs en temps é m(i)/p ù £ m(i)/p+1.
On obtient le résultat en sommant sur les étapes.
.2cm
Reprenons l'exemple du calcul du maximum, sur une PRAM EREW. On peut agencer ce calcul en temps
O(log n) à l'aide d'un arbre binaire. A l'étape un, on procède paire par paire avec é
n/2 ù processeurs, puis on continue avec les maxima des paires deux par deux etc. C'est
à la première étape qu'on a besoin du plus grand nombre de processeurs, donc il en faut
O(n). Formellement, si n=2m, si le
tableau A est de taille 2n, et si on veut calculer le maximum des n éléments de A en
position A[n], A[n+1],...,A[2n-1], on obtient le résultat dans A[1] après
exécution de l'algorithme:
for (k=m-1; k>=0; k--)
for each j from 2^k to 2^(k+1)-1 in parallel
A[j] = max(A[2j],A[2j+1]);
Supposons que l'on dispose maintenant de p < n processeurs. Le théorème de Brent nous dit
que l'on peut simuler l'algorithme précédent en temps O(n/p+log n),
car le nombre d'opérations total est m=n-1. Si on choisit p=n/log n, on obtient
la même complexité, mais avec moins de processeurs!
.2cm
Tout ceci nous donne à penser qu'il existe sans doute une bonne notion de comparaison des
algorithmes, sur des machines PRAM éventuellement différentes.
Soit P un problème de taille n à résoudre, et soit Tseq(n) le temps du meilleur
algorithme séquentiel connu pour résoudre P. Soit maintenant un algorithme parallèle
PRAM qui résout P en temps Tpar(p) avec p processeurs. Le facteur d'accélération
est défini comme:
et l'efficacité comme
Enfin, le travail de l'algorithme est Wp=pTpar(p)
Le résultat suivant montre que l'on peut conserver le travail par simulation:
Proposition
Soit A un algorithme qui s'exécute en temps t sur une PRAM avec p processeurs. Alors
on peut simuler A sur une PRAM de même type avec p' £ p processeurs, en temps
O(tp/p').
.3cm
En effet, avec p' processeurs, on simule chaque étape de A en temps proportionnel à
é p/p' ù. On obtient donc un temps total de
O(p/p't)=O(tp/p').
4.5 Tris et réseaux de tris
On a vu l'importance de l'existence d'un algorithme de tri en O(log n) pour les théorèmes
de la section précédente. On va se contenter ici de présenter un algorithme de
tri très simple, dit réseau de tri pair-impair, ceci dans un double but. Le premier est de montrer
que l'on peut paralléliser efficacement un algorithme de tri, et que l'on peut en déduire
des implémentations effectives. Le deuxième est de montrer
une classe particulière de machines PRAM, spécialement introduites pour ces types de problèmes,
qui sont les réseaux de tri.
Un réseau de tri est en fait une machine constituée uniquement d'une brique très simple, le
comparateur (voir figure 4.4). Le comparateur est un ``circuit'' qui prend
deux entrées, ici, a et b, et qui renvoie deux sorties: la sortie ``haute'' est min(a,b),
la sortie ``basse'' est max(a,b).
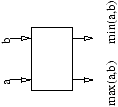
Figure 4.4: Un comparateur.
Donnons maintenant l'exemple du réseau de tri pair-impair.
Ce réseau est formé d'une succession de lignes de comparateurs. Si on désire trier n=2p
éléments, on positionne p copies du réseau formé de deux lignes, dont la première
consiste en p comparateurs prenant en entrées les p paires de fils 2i-1 et 2i, 1 £ i £ p
(étape impaire), et dont la seconde consiste en p-1 comparateurs prenant en entrées les p-1 paires
de fils 2i et 2i+1, 1 £ i £ p-1 (étape paire); voir la figure 4.5 pour
n=8. Bien sûr, il faut bien n=2p telles lignes, car si on suppose que l'entrée est ordonnée
dans le sens décroissant, de gauche à droite, il va falloir faire passer la valeur gauche (en haut)
à droite (en bas), ainsi que la valeur droite (en haut) à gauche (en bas).
Il y a un total de p(2p-1)=n(n-1)/2 comparateurs dans le réseau. Le
tri s'effectue en temps n, et le travail est de O(n3). C'est donc sous-optimal. Certes, moralement,
le travail est réellement de O(n2) (ce qui reste sous-optimal) car à tout moment, il n'y a que de l'ordre de n processeurs
qui sont actifs. C'est l'idée de l'algorithme que nous écrivons maintenant, mais que l'on ne peut
pas écrire dans les réseaux de tris, dans lequel on réutilise
les mêmes processeurs pour les différentes étapes du tri pair-impair.
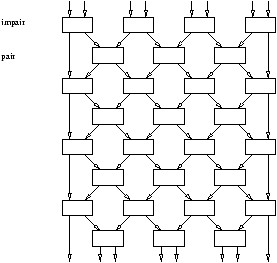
Figure 4.5: Réseau de tri pair-impair pour n=8.
Prenons néanmoins un peu d'avance sur les chapitres concernant la distribution, en indiquant
comment ces idées qui pourraient paraître bien peu réalistes, trouvent des applications
bien naturelles. Supposons que nous ayons un réseau linéaire de processeurs
dans lequel les processeurs ne peuvent communiquer qu'avec leurs voisins de
gauche et de droite (sauf pour les deux extrémités, mais cela a peu d'importance ici, et
on aurait pu tout à fait considérer un réseau en anneau comme on en verra à la section
8.3).
Supposons que l'on ait n données à trier et que l'on dispose de p processeurs, de telle
façon que n est divisible par p. On va mettre les données à trier par paquet de n/p
sur chaque processeur. Chacune de ces suites est triée en temps O(n/plog n/p). Ensuite
l'algorithme de tri fonctionne en p étapes d'échanges alternés, selon le principe du
réseau de tri pair-impair, mais en échangeant des suites de taille n/p à la place
d'un seul élément. Quand deux processeurs voisins communiquent, leurs deux suites de taille n/p
sont fusionnées, le processeur de gauche conserve la première moitié, et celui de droite, la
deuxième moitié. On obtient donc un temps de calcul en O(n/plog n/p +n) et un
travail de O(n(p+log n/p)). L'algorithme est optimal pour p £ log n.