Télécharger TD5.zip et extraire les fichiers dans le dossier du projet.
1 Introduction
Ce sujet aborde les arbres k-dimensionnels, ou arbres kd. Cette structure de données permet de trouver efficacement, parmi un ensemble de points de ℝk, le plus proche voisin d’un point donné.
Les arbres kd sont similaires aux arbres binaires de recherche, à ceci près que l’ordre utilisé pour répartir les descendants d’un nœud n entre les sous-arbres gauche et droit dépend de la profondeur de n dans l’arbre : on trie les nœuds alternativement suivant chacune de leurs k coordonnées.
Plus formellement, un arbre k-dimensionnel est un arbre binaire dont les nœuds contiennent chacun un point de ℝk. De plus, si p = (p0, …, pk − 1) est un point placé dans un nœud n à profondeur i et en notant r le reste de la division euclidienne de i par k :
pour tout point q = (q0, …, qk − 1) placé dans le sous-arbre gauche issu de n, on a qr < pr,
pour tout point q = (q0, …, qk − 1) du sous-arbre droit, on a qr ≥ pr.
(On convient que la profondeur de la racine est 0.)
class KDTree {int depth;double[] point; KDTree left; KDTree right;// Construit une feuilleKDTree(double[] point, int depth) {this.point = point;this.depth = depth; }}
De manière classique, on représente un arbre ou un sous-arbre par son nœud racine. Un nœud contient un point de ℝk, de type double[], et des pointeurs vers les sous-arbres gauche et droit. On stocke également dans chaque nœud sa profondeur dans l’arbre (champ depth).
Comme dans le cours, l’arbre vide est représenté par null.
2 Insertion
On souhaite ajouter une méthode qui insère un point a dans un arbre tout en préservant la propriété définissant les arbres kd. Pour cela, on a besoin de savoir si on doit placer le point a dans le sous-arbre gauche ou dans le sous-arbre droit.
2.1 Comparaison
Dans la classe KDTree, complétez la méthode boolean compare(double[] a)) qui renvoie true si le point a doit être inséré dans le sous-arbre droit, et false s’il doit être inséré dans le sous-arbre gauche.
En vue de la réutiliser dans la suite, on pourra isoler dans une méthode séparée le calcul de la différence de coordonnées qui intervient dans le choix.
Testez votre code avec TestCompare.
2.2 Insertion
Dans la classe KDTree, complétez la méthode KDTree insert(KDTree tree, double[] a) qui ajoute à l’arbre tree un nœud contenant le point a et renvoie la racine de l’arbre obtenu. La méthode d’insertion doit préserver la propriété définissant les arbres kd. (Attention à régler correctement la profondeur du point inséré !) On s’autorise à insérer plusieurs copies d’un même point.
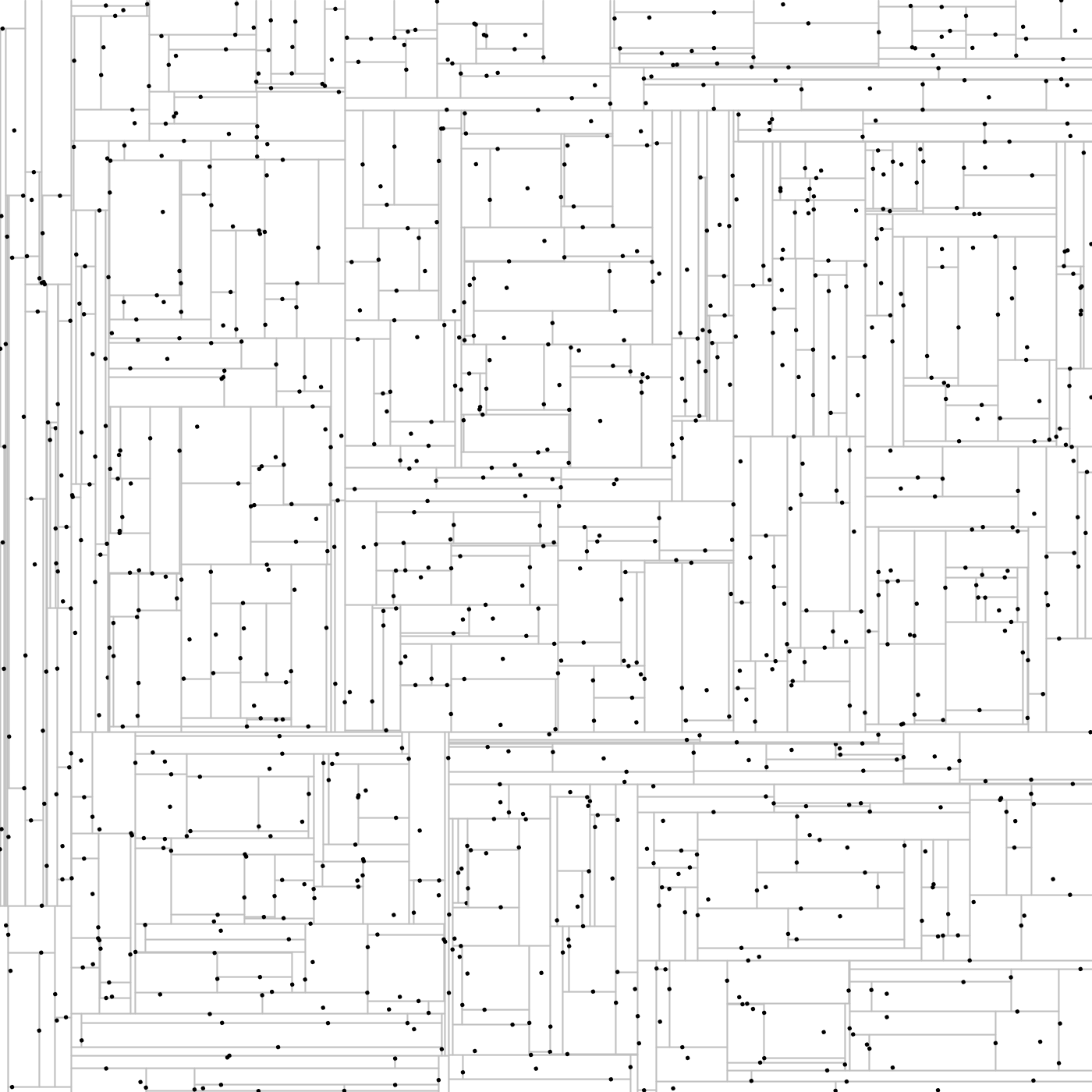
Testez votre code avec TestInsert et InteractiveClosest. La fenêtre produite par InteractiveClosest représente l’arbre 2-dimensionnel obtenu après avoir inséré successivement 50 points choisis uniformément dans [0,1]×[0,1]. Tapez '+' ou '-' pour avoir plus ou moins de points.
Déposez KDTree.java.
Voici par exemple ce que l’on obtient avec 1016 points :
3 Point le plus proche
On s’intéresse maintenant à la recherche du point d’un arbre kd qui est le plus proche d’un point a donné, au sens de la distance euclidienne.
3.1 Distance
Complétez la méthode double sqDist(double[] a, double[] b) qui calcule le carré de la distance entre deux points.
Dans la classe TestSqDist, écrivez quelques tests pour vérifier que sqDist fonctionne correctement.
Par exemple, le carré de la distance entre les points ( − 0.5, 1) et (0.5, − 1) est égal à 5. Testez quelques autres exemples représentatifs des entrées possibles. N’oubliez pas que sqDist doit fonctionner en toute dimension (k = 0, k = 1, k = 1000, …).
Déposez TestSqDist.java.
3.2 Version naïve
L’algorithme naïf pour retrouver le point le plus proche consiste simplement à parcourir tous les points de l’arbre, tout en maintenant dans une variable champion le point le plus proche rencontré jusque-là.
Complétez la méthode static double[] closestNaive(KDTree tree, double[] a) qui renvoie le point le plus proche du point a dans l’arbre tree, ou null si l’arbre est vide.
(Une méthode auxiliaire pourra être utile.)
Testez votre code avec TestClosestNaive.
Déposez KDTree.java.
3.3 Un algorithme plus efficace
La complexité de la méthode closestNaive précédente est linéaire en la taille de l’arbre. On peut faire beaucoup mieux en utilisant la structure de l’arbre kd.
On observe que pour tout sous-arbre t à profondeur i dans notre arbre kd, les points dans le sous-arbre gauche de t sont séparés des points dans le sous-arbre droit de t par l’hyperplan de coupure défini par x[i%k] = t.point[i%k].
Pour chercher le plus proche voisin d’un point a dans t, on peut donc commencer par chercher le plus proche voisin p dans le sous-arbre de t situé du même côté de l’hyperplan de coupure que a. Si a est plus proche de p que de l’hyperplan de coupure, alors il est inutile d’explorer l’autre sous-arbre de t (situation 1). Sinon, on doit considérer également t.point et les points dans le sous-arbre droit de t (situation 2).
Situation 1 : après avoir trouvé le point le plus proche dans le sous-arbre où a se trouve, il n’y a pas besoin d’explorer l’autre sous-arbre.
Situation 2 : après avoir trouvé le point le plus proche dans le sous-arbre où a se trouve, on ne peut pas exclure la possibilité que le point le plus proche se trouve dans l’autre sous-arbre.
Complétez les méthodes :
static double[] closest(KDTree tree, double[] a, double[] champion) qui recherche le point le plus proche point de a dans l’ensemble constitué par l’arbre tree et champion comme décrit ci-dessus ;
static double[] closest(KDTree tree, double[] a) qui renvoie le point le plus proche point de a ; si l’arbre est vide, on renvoie null.
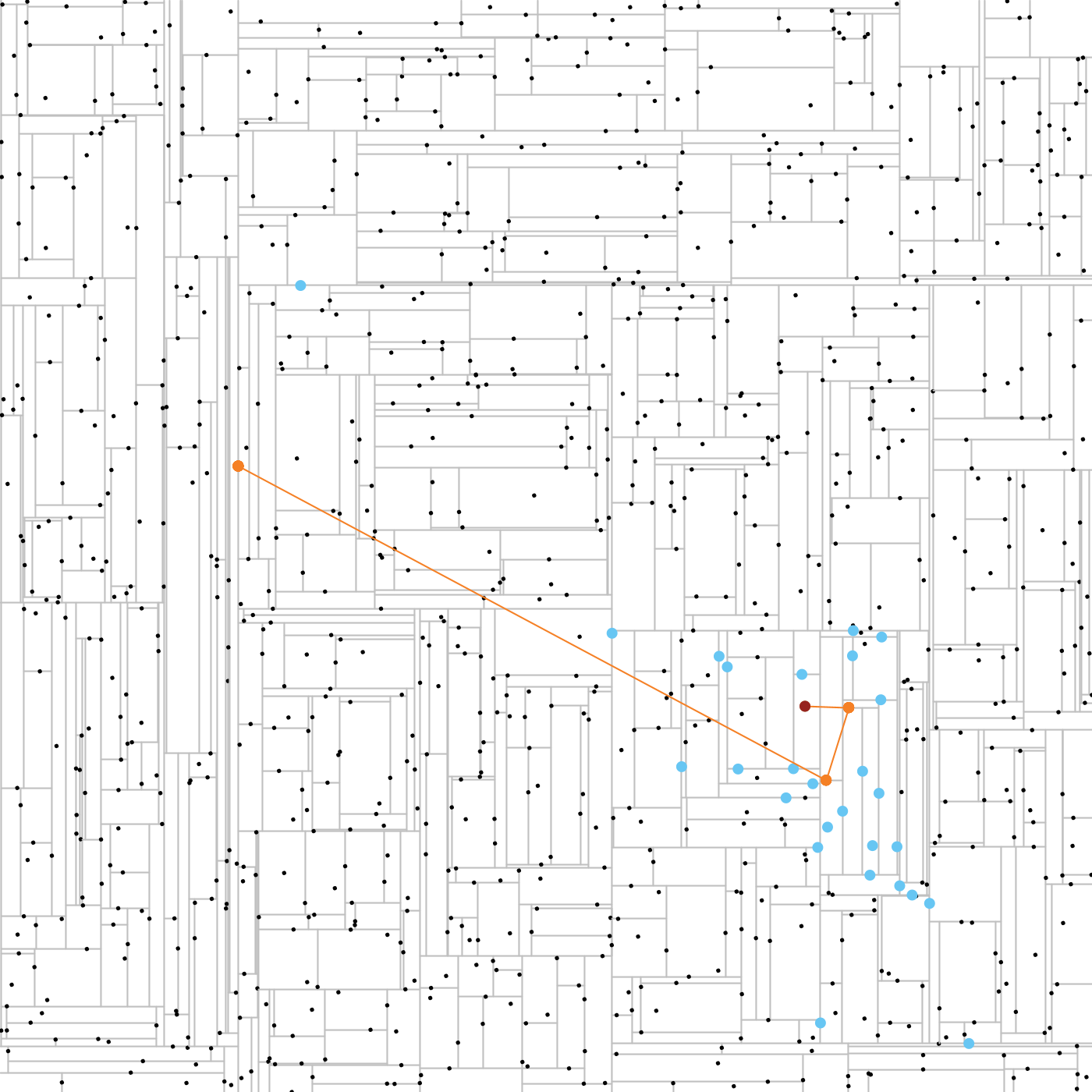
Au début de chaque appel récursif, la version à trois paramètres de closest devra appeler InteractiveClosest.trace(tree.point, champion) avec comme paramètre champion le point le plus proche connu à ce stade (voir le code fourni).
Testez votre code avec les classes TestClosestOptimized et InteractiveClosest.
La classe InteractiveClosest vous permet de visualiser le déroulement de l’algorithme. Cliquez pour rechercher le point le plus proche du curseur. Maintenez appuyé pour actualiser en continu. En bleu s’affichent les nœuds parcourus, en orange les champions successifs. Si la ligne orange est très brisée (disons plus de 10 points), c’est qu’il y a un problème.
Déposez KDTree.java.
4 Sélection d’une palette de couleur optimisée
Pour les applications courantes, les couleurs des images vues sur un écran sont codées avec 24 bits, 8 bits pour chacune des trois couleurs rouge, vert et bleu, ce qui donne un point. Pour compresser une image, le format d’image GIF sélectionne 256 couleurs, parmi les 16777216 possibles, pour représenter au mieux l’image. La méthode consistant à fixer 256 couleurs indépendamment de l’image, comme la palette web, donne de très mauvais résultats. Il faut sélectionner une palette de couleurs adaptée à l’image.
L’objectif de cette partie est d’écrire la fonction palette qui renvoie un objet de type Vector<double[]> contenant un nombre prescrit de points à même d’approcher les points d’un arbre kd donné.
Photo témoinPalette webPalette optimisée
4.1 Quelques fonctions auxiliaires
Complétez les méthodes suivantes :
int size(KDTree tree) qui renvoie le nombre de points dans l’arbre;
void sum(KDTree tree, double[] acc) qui calcule la somme des points de l’arbre tree, l’ajoute à acc;
double[] average(KDTree tree) qui renvoie le point isobarycentre (c’est-à-dire la valeur moyenne) des points de l’arbre, ou null pour un arbre vide.
Testez votre code avec TestAverage.
Déposez KDTree.java.
4.2 La méthode palette
La palette est composée à partir d’un arbre 3d contenant les couleurs de 20000 pixels choisis aléatoirement dans l’image. Les 256 couleurs seront obtenues en calculant l’isobarycentre des points de sous-arbres bien choisis.
Complétez la méthode static Vector<double[]> palette(KDTree tree, int maxpoints) qui renvoie un tableau de maxpoints couleurs en s’appuyant sur tree. Plusieurs stratégies sont possibles.
Testez votre code avec la classe ColorPalette. Un temps de calcul de plus d’une seconde ou un score supérieur à 10 indique un problème. Vos camarades d’une promo précédente sont descendus autour de 3.9. Partagez votre méthode si vous faites moins !
Il est normal de tâtonner. Commencez par une méthode naïve pour choisir maxpoints sous-arbres dont on prendra l’isobarycentre, puis raffinez. Au début, considérez maxpoints comme un ordre de grandeur plus qu’une contrainte stricte. Notez que dans notre application, l’arbre tridimensionnel tree dont on extrait une palette n’est pas forcément équilibré (c’est un arbre aléatoire).
Déposez KDTree.java.
4.3 Perspectives
Au-delà de la sélection de palette, les méthodes de diffusion d’erreur sont indispensables pour éviter les aplats inhérents aux méthodes remplaçant une couleur par son plus proche voisin dans une palette fixée. Mais c’est une autre histoire…