TD 1-2. Recherche du seuil de percolation : une application
d'Union-Find
par Julien Signoles à partir d'une idée de Benjamin Werner
(Sylvie Putot et Xavier Rival pour la première partie)
Introduction
Ce TD commence par une petite introduction à l'environnement de travail et à la prise en main de Java, avec l'écriture et l'exécution en ligne
de commandes, de quelques programmes simples en Java.
Ensuite, l'objectif du TD, qui se déroulera sur deux séances, est
de déterminer s'il y a ou non percolation à travers une grille du plan pavée de
cases noires et blanches, c'est-à-dire s'il existe ou non un chemin de cases
noires allant du haut au bas d'une telle grille. Ensuite, il s'agira d'estimer
la proportion de cases noires nécessaires à ce qu'il y ait percolation. Cette proportion est appelée le seuil de
percolation.
Pour cela, vous aurez à réaliser un programme, découpé en petites
fonctions élémentaires, que vous optimiserez ensuite étape par étape en étant
guidé(e) par le sujet. N'oubliez pas de tester les fonctionnalités que vous
écrivez chaque fois que possible, et au fur et à mesure !
Vous manipulerez ici les fonctions et structures de contrôle classiques de
Java, et vous y ferez un usage intensif des tableaux (entiers et booléens) et
des instructions de contrôle fondamentales. Vous programmerez notamment une
structure de données appelée
Union-Find permettant de
représenter efficacement des classes d'équivalence à l'aide de leurs
représentants canoniques. Elle permet d'optimiser la résolution de certains
problèmes dans des domaines variés, par exemple en théorie des graphes ou en
preuve automatique.
Suivi des TDs
Nous vous demandons lors des TDs de vous connecter sur la page web (login et mot de passe enex)
puis de charger vos solutions .java aux emplacements prévus,
afin que nous puissions suivre votre travail plus finement.
Vous pouvez tester vos programmes grâce à un script que nous
fournissons. Le script est accessible depuis les salles machines et
se nomme ~pierre-yves.strub/INF321-test/check. Pour tester
une question, il vous suffit d'exécuter la commande :
~pierre-yves.strub/INF321-test/check TD EXERCICE FICHERS...
où TD est le numéro du TD (ici, 1), EXERCICE est le
numéro de l'exercice et FICHIERS est l'ensemble de vos
fichiers Java.
Si vous utilisez Eclipse, ces derniers se trouvent à :
~/workspace/PROJET/src/
où PROJET est le nom du projet sous Eclipse.
E.g., pour tester la question 4 de ce TD, il vous suffit d'exécuter :
~pierre-yves.strub/INF321-test/check 1 4 ~/workspace/PROJET/src/*.java
Toutes les questions ne viennent pas avec une batterie de tests. Vous
pouvez obternir la liste des questions avec tests en exécutant :
~pierre-yves.strub/INF321-test/check -h
Documentation sur l'environnement de travail
Les pages qui suivent fournissent une documentation sur les manipulations de
base qui serviront pour les travaux dirigés de programmation en java. Par la
suite, vous pourrez les consulter à tout moment depuis la page du cours.
- quelques informations sur
l'environnement KDE
- les principales commandes utiles à la manipulation
des fichiers (ces commandes sont également décrites dans
le mémento).
- quelques informations sur le
navigateur Firefox
- pour éditer des programmes ou fichiers rapidement, on pourra utiliser
notamment l'éditeur Emacs, ou tout autre éditeur de
texte de votre choix. Nous verrons également dès la seconde partie de ce TD
l'environnement de développement
intégré Eclipse
(qui par exemple compile au fur et à mesure que vous écrivez, et vous signale
des éventuelles erreurs de syntaxe).
Une documentation plus complète est disponible sur
les pages
de Philippe Chassignet.
Premiers programmes et utilisation de la ligne de commandes
L'exercice qui suit permet de vérifier que l'on
maîtrise les trois phases de la mise en oeuvre d'un programme.
Pour les réaliser, il n'est pas nécessaire de comprendre
le langage Java.
Pour l'instant, il suffit de suivre fidèlement les instructions
données ci-dessous.
- Commencer proprement.
Ouvrir un terminal en cliquant sur l'icône  dans le bandeau en bas de l'écran. Ce terminal fait l'interface avec un shell interpréteur des commandes Unix.
Créez au moyen de la commande mkdir un répertoire
(par exemple INF321) pour placer les fichiers que
vous écrirez au cours des TD. Créez ensuite, à l'intérieur de ce
répertoire, un répertoire TD12 pour stocker les
programmes des deux premiers TDs. Placez-vous dans le répertoire TD12 au moyen de la commande cd INF321/TD12.
dans le bandeau en bas de l'écran. Ce terminal fait l'interface avec un shell interpréteur des commandes Unix.
Créez au moyen de la commande mkdir un répertoire
(par exemple INF321) pour placer les fichiers que
vous écrirez au cours des TD. Créez ensuite, à l'intérieur de ce
répertoire, un répertoire TD12 pour stocker les
programmes des deux premiers TDs. Placez-vous dans le répertoire TD12 au moyen de la commande cd INF321/TD12.
- Ecrire un programme à l'aide d'un éditeur de texte.
Le programme Emacs est l'éditeur de texte recommandé pour le début de ce premier TD. Plus généralement, il peut servir à créer ou modifier tout fichier texte.
Ceux qui le souhaitent peuvent aussi utiliser un autre éditeur qu'ils connaissent, voire un environnement de développement intégré comme Eclipse, que l'on verra dans la suite de ce TD.
On lance l'éditeur Emacs par la commande :
emacs &
Le caractère & en fin de commande sert
à lancer cette dernière en "arrière-plan", ce qui libère
le terminal pendant son exécution (qui dure ici aussi longtemps qu'on utilise
l'éditeur de texte) et permet ainsi d'entrer d'autres commandes,
pour la compilation par exemple.
Programme vide.
Voici le texte d'un programme vide :
// Programme Vide
// Ce programme minimal en Java ne fait rien !
class Vide {
// fonction principale (point d'entrée du programme)
public static void main(String[] args) {
} // fin de la fonction principale
} // fin du programme
Le sens exact des mots-clés class, public et static
sera étudié lorsque les concepts de la programmation orientée objets vous seront
enseignés. En attendant de lever leurs mystères, considérez-les comme des
conventions syntaxiques obligatoires.
Le tableau de chaînes de caractères args en argument de la
fonction main correspond aux arguments communiqués au programme par
l'utilisateur via la ligne de commandes.
Recopiez ce programme dans la fenêtre emacs que vous venez d'ouvrir.
Pour coller à la souris sous Emacs, il faut se placer avec le bouton
gauche au point d'insertion, puis cliquer avec le bouton du milieu.
Sauvez ensuite le fichier sous le nom Vide.java, dans
le répertoire INF321/TD12. Dans le menu File,
sélectionner Save Buffer As, et entrez le nom du fichier (dans la
terminologie d'Emacs, le buffer est la zone de mémoire qui contient la
version du texte en cours d'édition).
Compilez le fichier Vide.java puis exécutez
le programme.
La ligne
public static void main(String[] args) {
présente dans tout programme Java, introduit la fonction principale.
Ce programme se compile au moyen de la
commande :
javac Vide.java
et on l'exécute par :
java Vide
Le corps de la fonction principale étant vide, ce programme ne produit aucun
résultat.
Programme Bonjour.
On se propose maintenant de modifier ce programme pour qu'il affiche
le message Bonjour. On sauve donc le programme précédent sous le nom
Bonjour.java (dans Emacs, utilisez le
menu Files ... Save Buffer as).
Ensuite, on remplace
class Vide par class Bonjour et on insère
l'instruction :
System.out.println("Bonjour");
entre les lignes
public static void main(String[] args) {
et
}
On doit prendre tout de suite l'habitude de ne mettre qu'une instruction par
ligne et d'indenter correctement ses programmes. Pour
indenter une ligne sous Emacs, on appuie sur la touche
Tab.
Après l'avoir sauvé, ce programme sera compilé et
exécuté par les commandes ad-hoc.
Fichier vs programme.
Le nom du programme, ici Bonjour, qui figure dans la première
ligne class Bonjour n'est pas nécessairement identique au nom du
fichier. On peut ainsi remplacer
class Bonjour par class ProgrammeBonjour
Pour compiler le programme, on utilise le nom du fichier :
javac Bonjour.java
On peut remarquer en exécutant la commande ls que la
compilation produit un fichier qui porte le nom du programme suivi du
suffixe .class,
ici ProgrammeBonjour.class. Pour l'exécuter, on doit
utiliser le nom du programme.
java ProgrammeBonjour
-
Cas d'un programme qui ne termine pas.
Si on insère :
while (true)
avant
System.out.println("Bonjour");
on obtient un programme qui affiche Bonjour sans fin.
Pour l'interrompre, il faut entrer Ctrl-c dans la fenêtre
terminal.
Exercices de base
Les exercices qui suivent pointent un certain nombre de sources d'erreurs (ou
d'incompréhension) fréquentes. Ils ont donc pour but que vous les évitiez par la
suite.
Exercice 1 : les types primitifs
-
Calculer et afficher 20!, en utilisant une
variable i de type int puis une
variable n de type long. Pouvez-vous
expliquer la différence de comportement ?
-
Quel est le résultat des instructions suivantes :
double d = 0;
d = 1 + 1/2 + 1/3;
System.out.println(d);
Que faire pour obtenir un résultat plus conforme à l'intuition ?
-
Écrire un programme qui calcule et affiche à l'écran les
quantités :
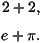
Les constantes
mathématiques qui interviennent ici sont des champs statiques de la
classe java.lang.Math dont voici
la documentation. Par
exemple, pour utiliser la constante Pi, il suffira d'écrire
Math.PI dans votre programme.
Exercice 2 : déboguer un programme
On programme rarement sans faire d'erreur. Il est donc important de savoir
détecter les erreurs dans un programme et les corriger rapidement. Pour cela, le
programmeur dispose de plusieurs outils qui lui facilitent considérablement la
tâche :
les messages d'erreur du compilateur, à regarder dans l'ordre
d'émission : ils sont relativement explicites en Java ; en particulier, le numéro
de la ligne où est détectée la première erreur est souvent pertinent ;
- les messages d'erreur à l'exécution ;
-
l'affichage de valeurs intermédiaires quand le programme ne produit pas le
bon résultat ;
- l'utilisation d'un débogueur comme celui intégré à Eclipse (ce point sera
abordé dans un prochain TD).
Il est très important de compiler et de tester son programme très
régulièrement, par exemple après l'écriture de chaque fonction.
Pour vous entraîner à déboguer rapidement, voici plusieurs versions erronées
d'un même programme censé calculer la valeur de n! où n est un entier entré au
clavier par l'utilisateur. L'objectif de cet exercice est de trouver l'erreur
dans chacun de ces programmes en utilisant les différents messages d'erreur
retournés par le compilateur ou à l'exécution.
Ces programmes utilisent la classe TC
documentée ici. Pour
vous en servir, il vous faut récupérer l'archive TC.jar et
ajouter en tête des fichiers l'instruction import tc.TC; .
Une fois l'archive TC.jar récupérée et installée dans le même
répertoire que vos programmes, il faut également adapter les commandes de
compilation et exécution, respectivement par (pour le fichier Bug1.java
contenant la classe
Bug1) :
javac -cp TC.jar:. Bug1.java
et
java -cp TC.jar:. Bug1.
Pour récupérer les huit fichiers suivants, il suffit par exemple de cliquer sur
chaque lien avec le bouton de droite et en choisissant Save Link As... dans le
menu. Prenez garde à les sauver dans le répertoire approprié (a
priori, INF321/TD12). On peut aussi tous les récupérer en
une seule fois sous la forme du fichier archive (zip)
suivant Bug.zip. Une fois ce fichier archive recopié
dans le répertoire adéquat, on retrouve les huit fichiers composants au moyen de
la commande unzip Bug.zip.
Pour le futur, vous avez ici un récapitulatif
des erreurs fréquentes, également accessible directement depuis la page du
cours.
Utilisation d'eclipse
Nous conseillons à présent d'utiliser l'environnement de développement Eclipse, qui est déjà installé sur toutes les
machines. Suivez les instructions
pour vous familiariser et configurer Eclipse. Pour utiliser la classe TC
dans Eclipse, suivez les instructions ici.
Seuil de percolation
Nous allons calculer une valeur approchée du seuil de percolation d'un chemin de
haut en bas dans une matrice contenant des cases noires et blanches. Pour ce
faire, nous allons noircir aléatoirement des cases et, après chaque étape, nous
allons détecter s'il existe un chemin fait de cases noires allant d'une case
quelconque du haut (première ligne) à une case quelconque du bas (dernière
ligne) de la matrice. Dans l'affirmative, la percolation sera atteinte. Le seuil
de percolation est la proportion de cases noires qu'il est probabilistiquement
nécessaire de noircir pour atteindre la percolation. Ce seuil est le même pour
toute matrice pas trop petite.
Pour représenter une matrice carrée M de taille N, nous allons
utiliser un tableau unidimensionnel T de taille NxN : la case
d'abscisse i et d'ordonnée j dans M (avec i
et j compris entre 0 et N-1) correspondra à l'élément
d'indice i.N + j dans T. Par exemple, voici ci-dessous
l'encodage d'une matrice de taille 3 par un tableau unidimensionnel de taille 9
(chaque case du tableau contient ici les coordonnées de la case de la matrice
qu'elle encode).
| (0,0) |
(0,1) |
(0,2) |
(1,0) |
(1,1) |
(1,2) |
(2,0) |
(2,1) |
(2,2) |
Une première solution
Exercice 3 : définition de la classe
Dans un nouveau fichier, définir une classe Percolation
contenant les constantes size, dans un premier
temps égal à 10, et correspondant à la taille d'une matrice
et length de valeur size *
size. Cette classe contiendra aussi un tableau statique de
booléens grid de taille length
correspondant à la matrice : une case contenant true
(resp. false) sera noire (resp. blanche).
Exercice 4 : fonction init
Définir une fonction init() sans argument initialisant
la matrice avec que des cases blanches.
Exercice 5 : fonction print
Définir une fonction print() sans argument affichant la
matrice sur la sortie standard. Les cases blanches seront représentées par le
caractère '-' (tiret) et les cases noires par '*'
(étoile). Faites bien attention à ce que les lignes correspondent bien à la
première dimension de la matrice et les colonnes à sa deuxième.
Par exemple, le tableau
| true |
false |
false |
true |
true |
false |
false |
true |
false |
(encodant une matrice 3x3) sera affiché comme suit :
**-
-**
---
Pour tester vos deux fonctions, ajouter une
fonction main initialisant la matrice avec que des
cases blanches sauf la case d'abscisse 2 et d'ordonnée 4, puis l'affichant.
Exercice 6 : percolation
- Définir une fonction random_shadow() noircissant au
hasard une des cases blanches de la matrice (en supposant qu'il en existe une)
et retournant l'indice correspondant. Pour ce faire, vous pourrez utiliser la
fonction Math.random qui retourne un nombre flottant
entre 0.0 (inclus) et 1.0 (exclus).
- Définir une fonction is_percolation(int n) retournant
le booléen true si et seulement s'il existe un chemin noir dans la
matrice, entre une de ses cases d'ordonnée 0 (le haut de la matrice)
et une de ses cases d'ordonnée size-1 (le bas de la matrice), et
passant par n. Vous prendrez garde à ne pas visiter deux fois la
même case. Pour ce faire, vous pourrez définir puis utiliser une fonction
récursive auxiliaire detect_path(boolean[] seen, int n,
boolean up) détectant un chemin de la case d'indice n au haut
(resp. bas) de la matrice si up est vrai (resp. faux), en considérant
le tableau seen des cases déjà visitées.
- Définir une fonction percolation() noircissant des
cases de la matrice au hasard, tant que sa percolation n'a pas eu lieu. Une
fois la percolation atteinte, elle retournera la proportion de cases noircies.
Exercice 7 : méthode de Monte-Carlo
- Définir une fonction montecarlo(int n) calculant une
estimation (entre 0 et 1) du seuil de percolation en
effectuant n simulations de percolation. Effectuer un tel calcul
approché par simulations successives est appelé la méthode de
Monte-Carlo (d'où le nom de la fonction). Elle est utilisée pour résoudre
efficacement plein de problèmes pratiques pour lesquels un calcul exact est
impossible ou trop coûteux.
- Modifier la fonction main de façon à afficher le seuil
de percolation d'une matrice blanche après n
simulations, n étant fournit par l'utilisateur via la ligne de
commandes (ou, dans Eclipse, via le panneau Arguments de la fenêtre
accessible à partir de Run -> Run Configurations). À l'aide de la
fonction System.currentTimeMillis(), afficher également
le temps d'exécution nécessaire pour atteindre le seuil de percolation.
- Essayer votre programme avec différentes tailles de matrice et différents
nombre de simulations.
Union-Find
La solution précédente n'est pas satisfaisante car le test de percolation est
trop inefficace. Nous allons utiliser une structure de données
appelée Union-Find pour optimiser notre recherche. Elle permet de
calculer efficacement une relation d'équivalence via le représentant
canonique de chacune des classes d'équivalence. Ici, deux indices de la matrice
sont équivalents s'ils sont sur un même chemin noir, de sorte que détecter la
percolation revient à détecter le fait qu'un élément du haut est équivalent à un
élément du bas de la matrice.
Exercice 8 : définir Union-Find
Nous allons d'abord programmer une première version de la structure
d'Union-Find, simple mais peu efficace (quick-find).
-
Dans un nouveau fichier UnionFind.java, créer une
classe UnionFind contenant un
tableau equiv contenant Percolation.length
entiers. On notera que, pour accéder à un élément statique x d'une
classe C, la syntaxe est C.x.
-
Ajouter à cette nouvelle classe une méthode find(int x)
retournant le représentant canonique associé à x.
-
Ajouter à cette nouvelle classe une méthode
union(int x, int y) réalisant l'union des classes
d'équivalence de x et y : les membres de la classe
d'équivalence de x auront pour nouveau représentant canonique celui
de y. Ce nouveau représentant sera in fine retourné par la
fonction.
Exercice 9 : utiliser Union-Find
Nous allons à présent utiliser notre structure d'Union-Find pour optimiser notre
programme détectant une percolation.
-
Modifier la fonction init de la
classe Percolation pour qu'elle initialise aussi le
tableau UnionFind.equiv en associant i à chaque
indice i : en l'absence d'un chemin de longueur supérieure ou égale à 2
passant par i, i est son propre représentant canonique dans sa
classe d'équivalence singleton.
-
Réécrire la fonction is_percolation de façon à utiliser la
fonction UnionFind.find. On pourra conserver en
commentaire l'implémentation précédante à titre de comparaison.
-
Définir une fonction propagate_union(int x) unissant la
classe d'équivalence de la case x (supposée noire) à tous ses voisins
noirs : à la fin de l'exécution de cette fonction, tous les voisins noirs
et x doivent appartenir à la même classe d'équivalence.
- Utiliser la fonction propagate_union(int x) à
l'endroit approprié.
Exercice 10 : Union-Find paresseux
La solution précédente n'est pas efficace car l'opération d'union est
trop coûteuse : sa complexité est linéaire en la taille de la matrice. Nous
allons effectuer une première optimisation au prix d'une
dégration de la complexité de la fonction find (de temps
constant à logarithmique). L'efficacité pratique sera
déjà globalement bien meilleure.
L'optimisation consiste, lors d'une union de deux classes
d'équivalence C1 et C2, à ne pas modifier tous les membres
d'une classe d'équivalence (disons C1), mais juste son représentant
canonique. Ce dernier est alors associé à celui de C2, de sorte que
des unions successives définissent une forêt dont chaque arbre ayant pour
racine r représente une classe d'équivalence ayant pour représentant
canonique r. Le tableau UnionFind.equiv
contient ainsi non
plus nécessairement les représentants canoniques des différentes classes
d'équivalence mais plutôt les différents pères de ces arbres. Ce principe est
illustré par le schéma suivant. Ce dernier montre le résultat de trois unions
successives sur un tableau de taille 9. En complément du contenu du
tableau UnionFind.equiv, les arbres non réduits à une
racine sont également représentés.
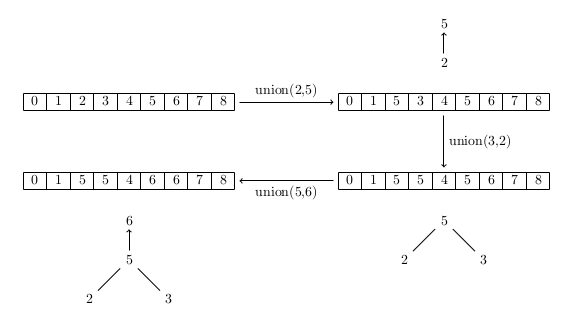
Coder cette optimisation en modifiant les fonctions find
et union. Comparer ensuite l'efficacité de cette
implémentation avec celle des autres versions.
Exercice 11 : complexité logarithmique
-
Lors d'une union union(x, y), une autre optimisation est
possible. En effet, pour l'instant, nous avons arbitrairement choisi de modifier
la classe d'équivalence de x pour qu'elle ait pour représentant
canonique celui de la classe d'équivalence d'y. Pour limiter les
hauteurs des arbres, on peut choisir de conserver pour représentant canonique
celui dont la hauteur de l'arbre correspondant à sa classe d'équivalence est la
plus grande : en intégrant un arbre strictement plus petit à sa racine, sa
hauteur ne changera pas. Cette optimisation permet de borner la
hauteur de chaque arbre par le logarithme du nombre de ses
éléments (voir poly). La complexité en temps de
chaque étape est donc alors également logarithmique.
Coder cette modification en ajoutant un tableau
d'entiers height de
longueur Percolation.length à la
classe UnionFind. L'élément d'indice i de ce
tableau contiendra la hauteur de l'arbre ayant i pour racine.
-
Une autre optimisation, appelé compression de chemin, consiste à
rapprocher de la racine les éléments rencontrés lors d'une recherche. De cette
façon, les arbres seront moins hauts. On peut simplifier cette optimisation en
se contentant de ne faire pointer chaque élément rencontré lors d'une recherche
que vers son grand-père dans l'arbre (plutôt que vers son père comme avant, ou
vers la racine pour la compression de chemin non simplifiée).
Coder la compression de chemin simplifiée et comparer l'efficacité de cette
implémentation avec celle des autres versions.