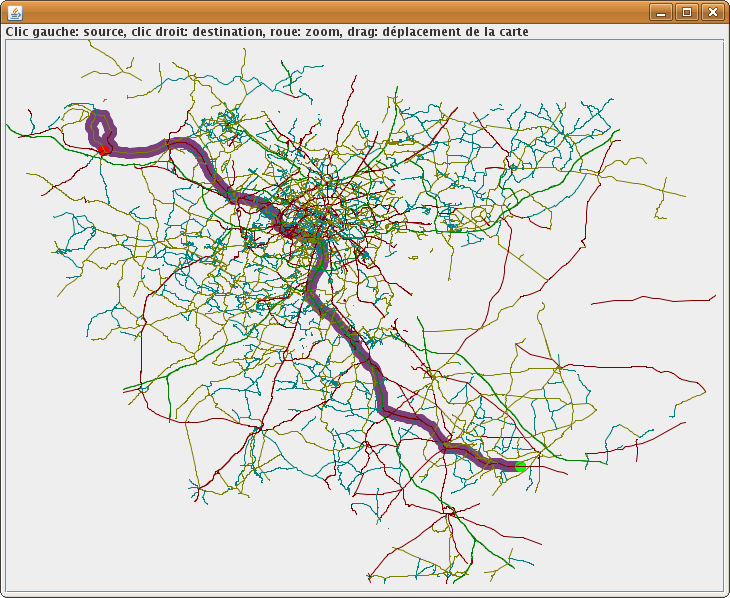
Notre but est d'écrire une partie d'un logiciel de cartographie et de recherche de chemin, comme l'on peut trouver dans un GPS de voiture ou dans les sites comme Via Michelin, Mappy ou Google Maps. Nous travaillerons à partir d'une carte extraite d'OpenStreetMap.
Nous nous intéresserons plus particulièrement aux structures de données utilisées dans la recherche d'un plus court chemin : étant donnés un point de départ et un point d'arrivée, trouver l'itinéraire prenant le moins de temps.
Les points sur la carte (intersections de routes, virages etc.) sont stockés sous la forme d'enregistrements de type Node. Voici l'enregistrement Node et son constructeur, à recopier dans GPS.java
class Node {
double lat;
double lon;
Node(double lat, double lon) {
this.lat = lat;
this.lon = lon;
}
}
Le champ lat contient la latitude du point, le champ lon sa longitude.
Afin de préparer l'affichage, nous avons besoin de connaître les points extrémaux de la carte considérée.
Question 1 : programmez les fonctions minLat, maxLat, minLon, maxLon prenant en argument un tableau de Node, Node[] t, et retournant respectivement la latitude minimale, la latitude maximale, la longitude minimale et la longitude maximale des points contenus dans t. Vous ne traiterez pas le cas où t est de longueur nulle. On rappelle que votre programme doit s'appeler GPS, c'est-à-dire être introduit par class GPS, et que les enregistrements sont toujours définis à l'extérieur du programme.
Pour tester vos fonctions, commencez par ajouter une fonction main à votre programme, dans laquelle vous appelerez la fonction test1() suivante :
static void test1() {
Node[] nodes = new Node[] { new Node(4.0, 5.0), new Node(3.0, 6.0),
new Node(8.1, 1.0), new Node(2.0, 2.2) };
System.out.println(minLat(nodes) + " " + maxLat(nodes) + " "
+ minLon(nodes) + " " + maxLon(nodes));
}
Vous devez obtenir l'affichage 2.0 8.1 1.0 6.0.
Lorsque l'utilisateur cliquera sur la carte, il faudra trouver le point de coordonnées le plus proche. Pour cela, on utilise la fonction distance(a,b) suivante (dont la définition ne nous intéresse pas ici), qui calcule la distance en mètres entre les points a et b (à l'aide d'une formule dite Haversine formula).
final static double EARTH_RADIUS = 6372797.560856;
static double distance(Node from, Node to) {
double latitudeArc = Math.toRadians(from.lat - to.lat);
double longitudeArc = Math.toRadians(from.lon - to.lon);
double latitudeH = Math.sin(latitudeArc * 0.5);
latitudeH *= latitudeH;
double longitudeH = Math.sin(longitudeArc * 0.5);
longitudeH *= longitudeH;
double tmp = Math.cos(Math.toRadians(from.lat))
* Math.cos(Math.toRadians(to.lat));
return 2.0 * Math.asin(Math.sqrt(latitudeH + tmp * longitudeH))
* EARTH_RADIUS;
}
Recopiez cette fonction, ainsi que la valeur du rayon de la Terre dans votre programme.
Question 2 : programmez une fonction static int findNearest(Node[] t, Node point) retournant l'indice du point de t le plus proche de point, en utilisant distance pour calculer la distance entre deux points. Si le tableau t est de longueur nulle, retournez -1.
Vous testerez vos fonctions en appelant la fonction test2() suivante :
static void test2() {
Node[] nodes = new Node[] { new Node(4.0, 5.0), new Node(5.0, 4.0),
new Node(3.0, 6.0), new Node(8.1, 1.0), new Node(2.0, 2.2) };
System.out.println(findNearest(nodes, new Node(4.1, 5.1)));
System.out.println(findNearest(nodes, new Node(3.1, 6.1)));
System.out.println(findNearest(nodes, new Node(8.0, 0.9)));
System.out.println(findNearest(nodes, new Node(2.0, 2.2)));
System.out.println(findNearest(nodes, new Node(4.0, 4.0)));
System.out.println(findNearest(nodes, new Node(5.0, 5.0)));
System.out.println(findNearest(nodes, new Node(4.999, 5.0)));
System.out.println(findNearest(nodes, new Node(4.99, 5.0)));
System.out.println(findNearest(new Node[0], new Node(4.99, 5.0)));
}
Vous devez obtenir l'affichage suivant :
0 2 3 4 0 1 1 0 -1
Il est parfois nécessaire de rechercher l'ensemble des points situés à moins d'une certaine distance d'une position sur la carte (par exemple pour implémenter la recherche des stations-service proches du véhicule de l'utilisateur du GPS).
Vous disposez de l'enregistrement IndicesList et de son constructeur, à recopier dans GPS.java :
class IndicesList {
int index;
IndicesList next;
IndicesList(int index, IndicesList next) {
this.index = index;
this.next = next;
}
}
Question 3 : programmez une fonction static void printIndicesList(IndicesList list) qui affiche les éléments de la liste list ; on affichera un élément par ligne.
Question 4 : programmez une fonction static IndicesList nearPoints(Node[] t, Node point, double thr) qui retourne la liste des indices i classés dans l'ordre croissant tels que distance(t[i], point) ≤ thr (l'indice le plus petit sera donc en tête de liste).
Vous testerez votre fonction en appelant la fonction test4() suivante :
static void test4() {
Node[] nodes = new Node[] { new Node(10.0, 2.0), new Node(4.0, 5.0),
new Node(5.0, 4.0), new Node(3.0, 6.0), new Node(8.1, 1.0),
new Node(2.0, 2.2) };
printIndicesList(nearPoints(nodes, new Node(4.0, 4.0), 250000));
}
Vous devez obtenir l'affichage suivant :
1 2 3
Pour trouver le plus court chemin, nous utiliserons un programme (qui sera fourni avec l'énoncé) basé sur l'algorithme de Dijkstra. Cet algorithme parcourt les points du réseau routier dans un certain ordre. Les points sont tous stockés dans un tableau de Node. Plutôt que de manipuler directement les enregistrements Node, on utilisera, pour représenter un Node, sa position dans le tableau, c'est-à-dire un entier i entre 0 et (n-1) pour une certaine valeur de n fixée. Les éléments avec lesquels nous travaillerons sont donc uniquement ces entiers.
Nous avons besoin d'une structure de données permettant de faire une file d'attente (on met des éléments en attente et on les fait sortir un par un), mais avec priorité : c'est l'élément le plus prioritaire qui sort.
Notre but est de programmer trois fonctions isEmpty, add et remove, qui servent respectivement à ajouter un élément avec une certaine priorité, à tester si la file est vide et à obtenir et retirer l'élément de plus grande priorité. Nous voulons que ces fonctions soient efficaces, c'est-à-dire, ici, qu'elles s'exécutent en un temps au plus proportionnel au logarithme du nombre d'éléments présents dans la file.
Pour cela, nous proposons d'implémenter la file de priorité par un tas binaire (heap en anglais) stocké dans des tableaux. La file est donc représentée par l'enregistrement PriorityQueue suivant :
class PriorityQueue {
int[] indicesInHeap;
int[] heap;
double[] priorities;
int heapCurrentLength;
PriorityQueue(int n) {
indicesInHeap = new int[n];
heap = new int[n];
priorities = new double[n];
heapCurrentLength = 0;
for (int i = 0; i < n; i++) {
heap[i] = indicesInHeap[i] = -1;
}
}
}
Recopiez la définition de l'enregistrement PriorityQueue dans GPS.java
Le constructeur PriorityQueue(int n) construit une file de priorité vide, dimensionnée pour pouvoir stocker des éléments compris entre 0 et n-1.
Les trois premiers champs sont des tableaux de même longueur n. À chaque instant, la file de priorité contient des éléments entiers entre 0 et n-1.
Le champ heapCurrentLength indique le nombre d'entiers actuellement dans la file. Initialement, la file est vide, donc le champ heapCurrentLength vaut zéro.
Le champ priorities est un tableau de double tel que la case priorities[i] contient la priorité de l'élément i s'il est présent dans la file.
Le tableau heap représente la file : il contient les éléments actuellement dans la file dans ses cases d'indice compris entre 0 et heapCurrentLength-1. Les cases d'indices supérieurs ou égaux à heapCurrentLength contiennent -1. L'ordre des éléments dans le tableau est défini par la propriété de tas expliquée plus loin.
Le tableau indicesInHeap contient les indices des éléments dans le tableau heap : si l'élément i est dans la file, alors indicesInHeap[i] désigne l'indice de la case du tableau heap où il se trouve (donc heap[indicesInHeap[i]] est égal à i). Sinon, indicesInHeap[i] vaut -1.
La propriété de tas qui définit la manière dont les éléments du tableau heap sont ordonnés est la suivante :
En résumé, les trois propriétés vérifiées par une file de priorité de ce type sont
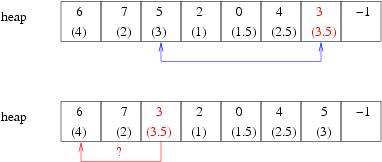
Voici un exemple de structure de données PriorityQueue pour n=8, qui vérifie les propriétés précédentes. heap, indicesInHeap et priorities sont donc des tableaux de longueur 8, et les éléments de la file sont des entiers entre 0 et 7.
A l'instant considéré, la file contient les 6 éléments suivants :
0, 2, 4, 5, 6, 7. Donc heapCurrentLength = 6.
Leurs priorités sont données dans le tableau priorities suivant :
priorities = [1.5, 0, 1, 0, 2.5, 3, 4, 2]
Autrement dit, l'élément 0 a la priorité 1.5,...
Le tableau heap contient ces 6 éléments ordonnés suivant la propriété de tas :
heap = [6, 7, 5, 2, 0, 4, -1, -1]
On vérifie que les cases d'indices supérieurs ou égaux à heapCurrentLength=6 contiennent -1 (Propriété [P1]). On vérifie aussi sur le dessin ci-dessous que l'ordre des éléments dans heap vérifie la propriété de tas (Propriété [P3]).
![heap vérifie [P3]](heap.jpg)
Le tableau indicesInHeap contient les indices des éléments dans le tableau heap (et -1 si l'élément n'est pas dans heap) : indicesInHeap = [4, -1, 3, -1, 5, 2, 0, 1]
On vérifie que les tableaux heap et indicesInHeap sont bien cohérents (Propriété [P2]).
![heap vérifie [P2]](heap2.jpg)
Question 5 : programmez une fonction static boolean isEmpty(PriorityQueue queue) qui retourne true si et seulement si la file queue est vide. (Indication : c'est très simple et cela peut tenir en une ligne.)
Vous testerez votre fonction en appelant la fonction test5() suivante :
static void test5() {
PriorityQueue queue = new PriorityQueue(20);
System.out.println(isEmpty(queue));
for (int i = 0; i < 15; i++) {
final int j = 6 ^ i;
queue.heap[i] = j;
queue.indicesInHeap[j] = i;
queue.priorities[j] = -i * 0.5;
}
queue.heapCurrentLength = 15;
System.out.println(isEmpty(queue));
}
Vous devez obtenir l'affichage suivant :
true false
Question 6 : programmez une fonction static void print(PriorityQueue queue) qui affiche le contenu du tableau heap de la façon suivante :
Cette fonction d'affichage vous servira pour contrôler vos calculs sur des exemples.
Vous testerez votre fonction en appelant la fonction test6() suivante :
static void test6() {
PriorityQueue queue = new PriorityQueue(20);
for (int i = 0; i < 12; i++) {
final int j = 6 ^ i;
queue.heap[i] = j;
queue.indicesInHeap[j] = i;
queue.priorities[j] = -i * 0.5;
}
queue.heapCurrentLength = 12;
print(queue);
}
Le résultat obtenu doit être identique au fichier ExempleQ06_resultat.txt. Vous pouvez tester si votre sortie est exacte en faisant java GPS > resultat06.txt puis diff ExempleQ06_resultat.txt resultat06.txt : s'il n'y a aucune différence, rien n'est affiché. Faites attention au fait que la moindre différence (même s'il y a une espace en trop) provoquera une erreur.
Voici le principe général de l'ajout d'un élément dans la file :
Question 7 : programmez une fonction static void swap(int[] t, int a, int b) qui intervertit les cases d'indices a et b du tableau pointé par t. (Indication : cela prend 3 lignes dans notre corrigé.)
Vous testerez votre fonction en appelant la fonction test7() suivante :
static void test7() {
int[] t = new int[10];
for (int i = 0; i < t.length; i++)
t[i] = i;
swap(t, 3, 7);
for (int i = 0; i < t.length; i++) {
System.out.println(t[i]);
}
}
Vous devez obtenir l'affichage suivant :
0 1 2 7 4 5 6 3 8 9
Question 8 : programmez la fonction static void bubbleSwap(PriorityQueue queue, int h1, int h2) qui intervertit les éléments d'indices h1 et h2 dans la file (elle doit donc non seulement intervertir les cases heap[h1] et heap[h2] mais aussi modifier indicesInHeap). (Indication: cette fonction est aussi assez simple et le code peut tenir en trois lignes).
Vous testerez votre fonction en appelant la fonction test8() suivante :
static void test8() {
PriorityQueue queue = new PriorityQueue(20);
for (int i = 0; i < 16; i++) {
final int j = 6 ^ i;
queue.heap[i] = j;
queue.indicesInHeap[j] = i;
queue.priorities[j] = -i * 0.5;
}
queue.heapCurrentLength = 16;
bubbleSwap(queue, 4, 8);
print(queue);
for (int i = 0; i < 16; i++) {
System.out.println(queue.indicesInHeap[i]);
}
}
Le résultat obtenu doit être identique au fichier ExempleQ08_resultat.txt. Vous pouvez tester si votre sortie est exacte en faisant java GPS > resultat08.txt puis diff ExempleQ08_resultat.txt resultat08.txt : s'il n'y a aucune différence, rien n'est affiché.
Question 9 : programmez la fonction static void add(PriorityQueue queue, int i, double priority) qui rajoute l'élément i avec la priorité priority dans la file. Dans cette question, on supposera que l'élément est absent de la file avant son ajout.
Si la file est déjà pleine, l'ajout est impossible. Nous vous suggérons de faire échouer dans ce cas le programme à l'aide de Ppl.failWith.
Indication : cette fonction peut consister essentiellement en une boucle de quelques lignes qui fait « remonter » l'élément par échanges successifs tant qu'il est trop prioritaire pour rester où il est. Ne cherchez pas trop compliqué, la procédure du corrigé, écrite aéré, fait 19 lignes.
Vous testerez votre fonction avec l'appel à la fonction test9() suivante :
static void test9() {
final int N = 16;
PriorityQueue queue = new PriorityQueue(N);
for (int i = 0; i < N; i++) {
add(queue, i ^ 6, (i >> 2) | ((i & 3) << 2));
}
print(queue);
}
Le résultat obtenu doit être identique au fichier ExempleQ09 _resultat.txt. Vous pouvez tester si votre sortie est exacte en faisant java GPS > resultat09.txt puis diff ExempleQ09_resultat.txt resultat09.txt.
Question 10 : modifiez la fonction add(PriorityQueue queue, int i, double priority) pour qu'elle traite, de plus, le cas où l'élément i est déjà présent :
Vous testerez votre fonction en appelant la fonction test10() suivante :
static void test10() {
final int N = 16;
PriorityQueue queue = new PriorityQueue(N);
for (int i = 0; i < N; i++) {
add(queue, i ^ 6, (i >> 2) | ((i & 3) << 2));
}
for (int i = 0; i < N; i += 2) {
add(queue, i, 100 + i);
}
for (int i = 1; i < N; i += 2) {
add(queue, i, -10);
}
print(queue);
}
Le résultat obtenu doit être identique au fichier ExempleQ10_resultat.txt. Vous pouvez tester si votre sortie est exacte en faisant java GPS > resultat10.txt puis diff ExempleQ10_resultat.txt resultat10.txt.
Pour faciliter le déboguage du code, il est utile de disposer de fonctions vérifiant que les structures de données sont bien formées. Dans le cas d'une structure PriorityQueue, il faut que les deux tableaux heap et indicesInHeap soient en bijection : les éléments i pour qui indicesInHeap[i] n'est pas -1 doivent vérifier heap[indicesInHeap[i]]=i. Les cases non utilisées de heap doivent valoir -1 et la propriété de tas doit être vérifiée (pour tout 0<k<heapCurrentLength, priorities[heap[k]]≤priorities[heap[⎣(k-1)/2⎦]]).
Question 11 : programmez une fonction static void check(PriorityQueue queue) qui procède à ces vérifications et, au cas où il y aurait un problème, imprime un message explicatif sur l'écran et termine le programme avec Ppl.failWith. S'il n'y a aucun problème, la fonction n'affichera rien.
Vous testerez votre fonction avec l'appel à la fonction test11() suivante , qui utilise la fonction intermédiaire checkQueue (Ppl.failWith fait normalement terminer immédiatement le programme avec un message d'erreur, mais pour les besoins de test11 nous avons remplacé ce comportement par l'affichage de false. Sinon, true est affiché.)
static void test11() {
{
PriorityQueue queue = new PriorityQueue(20);
for (int i = 0; i < 15; i++) {
final int j = 6 ^ i;
queue.heap[i] = j;
queue.indicesInHeap[j] = i;
queue.priorities[j] = -i * 0.5;
}
queue.heapCurrentLength = 15;
System.out.println(checkQueue(queue));
double old = queue.priorities[3];
queue.priorities[3] = 0;
System.out.println(checkQueue(queue));
queue.priorities[3] = old;
queue.heap[0] = 22;
System.out.println(checkQueue(queue));
queue.heap[0] = 3;
System.out.println(checkQueue(queue));
}
}
static boolean checkQueue(PriorityQueue queue) {
try {
check(queue);
return true;
} catch (RuntimeException exn) {
return false;
}
}
Le résultat obtenu doit être :
true false false false
L'élément le plus prioritaire est dans la case d'indice 0 de la file. Il est donc trivial de le récupérer. Le problème est de le supprimer tout en maintenant la propriété de tas. Trois cas se présentent :
Question 12 : programmez une fonction static int remove(PriorityQueue queue) qui supprime l'élément x le plus prioritaire de la file, remet la file en bon état et retourne x.
Vous testerez votre fonction en appelant la fonction test12() suivante :
static void test12() {
final int N = 16;
PriorityQueue queue = new PriorityQueue(N);
for (int i = 0; i < N; i++) {
add(queue, i ^ 6, (i >> 2) | ((i & 3) << 2));
}
for (int i = 0; i < N; i += 2) {
add(queue, i, 100 + i);
}
while (!isEmpty(queue)) {
System.out.println(remove(queue));
}
for (int i = 1; i < N; i += 2) {
add(queue, i, i);
}
while (!isEmpty(queue)) {
System.out.println(remove(queue));
}
}
Le résultat obtenu doit être identique au fichier ExempleQ12_resultat.txt.
Nous avons choisi une implémentation de file de priorité par un « tas binaire » car avec cette structure de donnée les ajouts et suppression d'éléments se font en temps au maximum proportionnel à log n où n est le nombre d'éléments dans la file... du moins si les fonctions sont correctement programmées.
Question 13 : testez vos fonctions avec l'appel à test13() suivante :
static void test13() {
final int N = 500000;
PriorityQueue queue = new PriorityQueue(N);
for (int i = 0; i < N; i++) {
add(queue, i ^ 6, (i >> 2) | ((i & 3) << 2));
}
for (int i = 0; i < N; i += 2) {
add(queue, i, 100 + i);
}
while (!isEmpty(queue)) {
remove(queue);
}
for (int i = 1; i < N; i += 2) {
add(queue, i, i);
}
}
Ce programme doit prendre de l'ordre d'une seconde (ou moins) pour s'exécuter. Le temps d'exécution peut être obtenu par la commande time java GPS (le temps est indiqué par la rubrique « user »).
Nous vous fournissons une implémentation de l'algorithme de Dijkstra de plus court chemin ainsi que des exemples de résultats. Cet algorithme fait appel à votre file de priorité. Téléchargez Dijkstra.java et compilez-le.
Si vous lancez java Dijkstra 30000 40000, vous devez obtenir :
iteration count = 173601 1h 8m 42s 934
Exécutez à présent le programme graphique par java -Xmx512M GraphView (l'option -Xmx512M alloue plus de mémoire au programme). Vous pouvez choisir l'échelle de la carte à l'aide de la molette de la souris, le point de départ avec le bouton gauche et le point d'arrivée avec le bouton droit et déplacer la carte par drag and drop. Le trajet optimal est affiché en trait rose large.
L'algorithme de Dijkstra parcourt les points du réseau routier en commençant par le point de départ de l'utilisateur, dans l'ordre croissant des distances au point de départ. Pour chaque point parcouru, on note le point d'où l'on venait pour l'atteindre par le chemin le plus court. Quand on atteint le point de destination, on sait donc comment l'atteindre de la façon la plus rapide.
L'algorithme de Dijkstra a un défaut : il parcourt tous les points du graphe situés à une distance inférieure à celle de la destination. Dans le cas d'un trajet dans une grande carte, cela peut être coûteux. Il semble absurde de parcourir des points situés loin dans une direction opposée à celle de la destination !
L'algorithme de Dijkstra parcourt les points x du graphe dans l'ordre croissant du temps de parcours depuis le point de départ o, d(x,o). Dans l'algorithme A*, on parcourt les points dans l'ordre croissant des valeurs de d(x,o)+e(x,f) où e(x,f) est un minorant de d(x,f), le meilleur temps de parcours entre x et la destination f. On pourra prendre par exemple pour e(x,f) le quotient de la distance GPS.distance(nodes[x], nodes[f]) et de la vitesse maximale (130000 m/h, la fonction distance fournit une distance en mètres).
On démontre facilement que si 0 ≤ e(x,f) ≤ d(x,f), alors le trajet optimal est trouvé pour x=f.
Question 14 : modifiez la fonction findPath de recherche (dans Dijkstra.java) pour remplacer l'algorithme de Dijkstra par l'algorithme A*. (Indication : il y a une seule ligne à modifier.)