Dans ce TP, nous nous proposons d'étudier le problème de la
satisfiabilité d'une formule booléenne (boolean satisfiability en
anglais), plus connu sous le nom de SAT. L'énoncé
du problème est très simple. On considère \(n\) variables booléennes
\(v_1, \dots, v_n\), dont la valeur est donc soit true soit
false et une formule \(\phi\) donnée sous forme
CNF. La formule \(\phi\) s'écrit donc comme une conjonction de
Par example, la formule \(\phi_1=(v_1\wedge \neg v_2)\vee (v_2\wedge \neg v_1)\) est satisfiable par les modèles (\(v_1\)=true, \(v_2\)=false) et (\(v_1\)=false, \(v_2\)=true). La formule \(\phi_2=v_1\wedge v_2\wedge (\neg v_2\vee \neg v_1)\) elle n'est pas satisfiable.
Le problème SAT est un problème fondamental en informatique. C'est le premier problème à avoir été classé comme NP-complet , ce qui signifie que, sauf si on prouve que P=NP, il n'existe pas de méthodes non-exponentielles permettant de décider si une formule est SAT ou UNSAT. Cependant, de très nombreux problèmes de décision en informatique peuvent se réduire à prouver la satisfiabilité d'une formule booléenne. Par exemple, la vérification de circuits électriques comme ceux présents dans les micro-processeurs des ordinateurs, ce qui a conduit beaucoup de chercheurs à développer des algorithmes efficaces en moyenne pour résoudre SAT. Voir ici pour quelques exemples de problèmes mathématiques qui peuvent s'encoder comme une (très grande) formule SAT.
Dans ce TP, nous allons implémenter un SAT solver en JAVA, c'est-à-dire un programme qui détermine automatiquement si une formule \(\phi\) donnée est satisfiable (on dira que \(\phi\) est SAT) ou insatisfiable (on dira que \(\phi\) est UNSAT). Dans le cas où \(\phi\) est SAT, le programme devra également donner un modèle qui évalue \(\phi\) à true.
Dans un premier temps, nous allons vous aider à implémenter un solveur raisonnablement efficace. Puis, à la manière des compétitions de solveurs SAT (SAT competition), vous pourrez comparer entre vous les performances de vos solveurs et nous vous donnerons des pistes pour améliorer votre solveur.
Attention. Nous allons vous fournir une partie du code pour ce projet, notamment un parseur de formules booléennes écrites dans le format DIMACS CNF. Pour que ce parseur fonctionne, il est important que vous utilisiez exactement les noms de classes demandés et que vos classes disposent des constructeurs et méthodes décrites dans le sujet. De même, à la fin du TD, votre code sera automatiquement testé par un programme qui contrôlera vos réponses et mesurera le temps d'exécution. Ce programme suppose que vos classes disposent de méthodes avec des noms et des types bien spécifiés, faites donc bien attention à respecter scrupuleusement les consignes données dans ce TD.
Attention bis. Enfin, toujours pour faciliter le test automatique, nous vous demanderons de fournir l'ensemble de vos classes dans un seul fichier TD910.java. Vous ne devrez donc toujours déposer que le fichier TD910.java. Votre travail ne sera pas pris en compte si vous déposez un fichier dont le nom n'est pas TD910.java.
Comme dit précédemment, on s'intéresse à la satisfiabilité de formules écrites sous Forme Normale Conjonctive (FNC, ou CNF en anglais), c'est-à-dire sous une forme normalisée qui est une conjonction de clauses, c'est à dire une conjonction de disjonctions de littéraux. Dans un premier temps, nous allons définir la structure de données permettant de représenter ces formules, et écrire un premier programme qui lit une telle formule dans un fichier et la stocke dans cette structure de donnée. Nous vous fournissons dans ce qui suit un parseur permettant de lire des formules au format DIMACS CNF, vous n'avez donc pas à vous préoccuper de ce format des fichiers exemple.
Commencez par créer un répertoire TD910 sous Eclipse, ainsi qu'une première classe TD910 qui servira à lancer les tests. Toutes vos autres classes devront se trouver dans le fichier TD910.java.
Dans un premier temps, il faut construire la structure de données permettant de représenter les formules logiques. Respectez bien les noms des classes et les profils des constructeurs indiqués, car ceux-ci sont utilisés dans le parseur de formules que l'on vous fournit pour lire les formules dont on souhaite vérifier la satisfiabilité.
Un litteral est défini par un champs entier indiquant le numéro de variable et un champ booléen spécifiant si on considère la variable ou sa négation. Nous numéroterons les variables de 1 à N.
class Litteral {
int var;
boolean neg;
}
Notons xi la variable booléenne de numéro i, si neg vaut false le litteral représente xi, sinon il représente
sa négation ¬ xi.
Ajouter un constructeur public Litteral (int v, boolean n).
Déposer votre programme TD910.javaUne clause est définie par un tableau de littéraux. Elle représente la disjonction des littéraux contenus dans le tableau, litterals[0] ∨ litterals[1] ∨ ... ∨ litterals[litterals.length-1].
class Clause {
Litteral[] litterals;
}
Ajouter un constructeur public Clause(Litteral[] lit).
Déposer votre programme TD910.java
Une formule est définie par un tableau de clauses et le nombre de variables intervenant dans la formule. Elle représente la conjonction des clauses contenu dans le tableau, clauses[0] ∧ clauses[0] ∧ ... ∧ clauses[clauses.length-1].
class Formula {
Clause[] clauses;
int nbVar;
}
Ajouter un constructeur public Formula (Clause[] c, int n).
Déposer votre programme TD910.java
Ajouter à chacune des classes précédentes une méthode public String toString() qui retourne l'affichage respectivement du litteral, de la
clause ou de la formule sous forme de chaînes de caractères. La définition de cette méthode permet ensuite d'afficher le contenu d'un objet obj par l'instruction System.out.println(obj), comme sur les types sur lesquels elle existe déjà par défaut (int,float,char,String, etc).
On suggère de noter - la négation, \/ la disjonction et /\ la conjonction.
Télécharger le fichier CNFParser.java. La classe CNFParser implémente un parseur de formules au format DIMACS CNF. Elle contient une méthode parseCNFInput() qui lit la formule sur l'entrée standard. Pour lire une formule depuis un fichier test1.cnf (par exemple), il est donc nécessaire de re-diriger l'entrée standard pour que la lecture se fasse depuis le fichier avec la commande TC.lectureDansFichier("test1.cnf") qui est fournie par la classe TC.
Tester, dans le main d'une nouvelle classe TD9, la lecture et l'affichage de la formule contenue dans le fichier test1.cnf. Par exemple, l'affichage de la formule devrait ressembler à :
1\/(-3) /\
2\/3\/(-1)
Déposer votre programme TD910.java
Changer le main pour que le nom du fichier contenant la formule soit passé en ligne de commande, et tester avec d'autres fichiers, disponibles ici : test_files_1.zip.
Dans cette partie, nous allons implémenter un premier algorithme de résolution du problème, par exploration de l'ensemble des choix possibles. Une formule logique est satisfiable s'il est possible d'associer une valeur logique booléenne à chacune de ses variables, de manière à ce que cette formule soit vraie.
Votre solveur doit vérifier si une formule est satisfiable. Si elle l'est, il doit afficher sur une ligne SAT : , suivi d'une solution, sous la forme pour chaque variable de son numéro, précédé d'un '-' si elle est affectée à la valeur faux. Si la formule n'est pas satisfiable, il doit afficher le mot UNSAT.
On va coder ces fonctions partielles en utilisant le type encapsulé Boolean (voir ici pour la doc complète). Une variable de type Boolean est un objet compatible avec les boolean true et false, mais qui peut aussi valoir null. En fait, si on fait des opérations entre boolean et Boolean, ce sont des méthodes de la classe Boolean qui seront utilisées pour la conversion : il faudra donc avant toute opération de ce style tester si l'objet de type Boolean est non null, vous aurez sinon une NullPointerException!
Définir une classe Model qui représente une fonction partielle des variables vers les booléens. Une variable sera représentée par un entier allant de 1 à n où n est le nombre total de variables dans la formule, la classe Model doit donc définir une fonction des entiers vers les Boolean. Cette classe devra avoir :
2 -3 5.On veut écrire une méthode Boolean eval(Model m) dans la classe Formula. Comme un modèle \(m\) pourra ne pas affecter une valeur à toutes les variables de la formule, il est possible qu'on ne puisse évaluer complètement la formule dans \(m\): la fonction d'évaluation est une fonction partielle, qui retourne true si toutes les clauses de la formule s'évaluent à vrai pour le modèle m, false si l'une s'évalue à faux, et null si la satisfiabilité de f ne peut pas être décidée dans le modèle m. Les 3 questions qui viennent vous aident à construire cette méthode.
Ajouter une méthode Boolean eval(Model m) dans la classe Litteral, qui (en utilisant la méthode getVar de la classe Model) évalue la valeur d'un littéral dans le modèle m, et renvoie null si la variable apparaissant dans le littéral est non valuée.
Déposer votre programme TD910.java
Ajouter une méthode Boolean eval(Model m) dans la classe Clause, qui évalue la clause dans le modèle m,
et renvoie null si on ne peut pas évaluer la clause.
Attention à ne pas retourner null trop tôt:
une variable est réellement nécessaire uniquement s'il n'y a pas de littéral dans la clause qui s'évalue à vrai!
Il va donc vous falloir tester tous les littéraux et ne retourner null que si :
En déduire la méthode Boolean eval(Model m) dans la classe Formula. De la même manière, un appel f.eval(m) retournera null si la satisfiabilité de f ne peut pas être décidée dans le modèle m.
Déposer votre programme TD910.java
Tester votre méthode en évaluant la formule donnée dans le fichier test2.cnf avec les modèles suivants:
\[
m_1=\left(\begin{array}{c}1\mapsto {\tt true}\\ 2\mapsto {\tt false}\\3\mapsto{\tt false}\\4\mapsto {\tt false}\\5\mapsto{\tt true}\\6\mapsto {\tt true}\end{array}\right)\qquad
m_2=\left(\begin{array}{c}1\mapsto {\tt true}\\4\mapsto {\tt false}\\5\mapsto{\tt true}\\6\mapsto {\tt true}\end{array}\right)\qquad
m_3=\left(\begin{array}{c}2\mapsto {\tt false}\\3\mapsto{\tt false}\\4\mapsto {\tt false}\\5\mapsto{\tt false}\end{array}\right)
\]
Vous devriez obtenir true pour \(m_1\), false pour \(m_3\) et null pour \(m_2\).
Definir une classe Instance qui a pour champs une formule et un modèle. Cette classe aura un constructeur Instance(Formula f,Model m) qui construit une nouvelle instance. Ce constructeur devra créer une copie du modèle m. Définir une fonction Boolean solve(), qui retourne true si le modèle satifait la formule, false si une clause au moins s'évalue à faux, et retourne null si on ne peut pas décider avec le modèle courant.
Ajouter une classe Solver contenant une méthode static Model solve(Formula f) qui retourne un modèle qui satisfait la formule f, ou null s'il n'en existe pas, c'est-à-dire si la formule n'est pas satisfiable. Attention, il est très important de respecter exactement les nom de la classe et de la méthode, ils seront utilisés dans les tests automatiques.
On procèdera par exploration (quasi) exhaustive des possibilités. Pour cela on suggère d'utiliser la classe Instance définie ci-dessus, en partant de l'instance dont le modèle ne contient que des variables sans valeur. Si le modèle s'évalue à vrai on retourne true, s'il s'évalue à faux on retourne false. Enfin si l'évaluation de la formule nécessite la valeur d'une variable non encore affectée, on va créer deux nouvelles instances du problème, dans lesquelles on choisira une variable non encore affectée et qui prendra respectivement la valeur vraie et faux, et ainsi explorer récursivement les possibilités jusqu'à avoir trouvé une solution ou avoir tout exploré.
De cette facon, on explore potentiellement toutes les possibilités, mais on va aussi couper certains sous-arbres lorsque la formule est déjà insatisfiable avec l'affectation de seulement une partie des variables. La recherche reste cependant très exhaustive.
Indice Pour choisir un litteral libre, on pourra :
En pratique, on suggère d'utiliser une pile pour gérer des évaluations
d'instances, en partant d'une pile contenant l'instance dont le modèle ne contient que des variables sans valeur.
Si l'évaluation de la formule dans le modèle courant nécessite la valeur d'une variable non affectée, on crée deux nouvelles instances
comme décrit ci-dessus, et on les empile.
On dépile et évalue ensuite les instances jusqu'à avoir trouvé une solution ou jusqu'à ce que la pile soit vide; on a alors exploré toutes les possibilités.
Pour gérer la pile, on pourra utiliser la classe LinkedList:
après avoir ajouté en tête de fichier la ligne
import java.util.LinkedList;on pourra dans le programme créer une liste d'objets de la classe Instance par l'instruction
LinkedList⟨Instance⟩ stack = new LinkedList⟨Instance⟩();et enfin utiliser les méthodes push, pop et isEmpty() pour définir et utiliser une pile.
Tester votre solveur sur les exemples test1.cnf à test5.cnf. Ce sont des exemples assez simples avec peu de variables. Nous vous fournissons un programme de test TestQ3.java qui execute votre solveur sur les fichiers test1.cnf à test5.cnf et verifie les resultats.
Déposer votre programme TD910.javaLors de ce depot, une procedure de test automatique est lancee. La procédure de test est identique à celle utilisée pour la pâle machine d'INF311. Automatiquement, un script récupère vos dépôts (un fichier unique contenant toutes les classes), et lance votre solveur sur une série de formules de tests. Le temps de calcul total est mesuré ainsi que le nombre de résultats corrects.
Pour voir les résultats, aller sur cette page. Vous y verrez un tableau contenant l'ensemble des dépôts de chaque élève et le résultat de la compilation : OK si tout s'est bien passé, ou bien le message d'erreur. Ensuite, en suivant les liens en haut de page, vous aurez accès au classement des solutions par ordre croissant de temps d'exécution.
Important Un time-out est utilisé pour éviter de sur-charger la machine de correction. Donc, si votre programme met plus de 45 seconds pour résoudres les formules test1.cnf à test5.cnf, votre résultat n'apparaitra pas dans les classements.
La méthode que vous venez de développer pour résoudre SAT montre très vite ses limites pour des problèmes avec plus de 10 variables. En effet, un parcours exhaustif de tous les modèles n'est possible que pour peu de variables. Par exemple, pour résoudre la formule \( (1\vee 2\vee 3)\wedge (\neg 1\vee \neg 2)\wedge \neg 3 \) , la méthode naïve revient à construire l'arbre suivant, où chaque noeud représente une variable et une flèche rouge signifie qu'on a fixé la variable à true dans le modèle, et une flèche bleue signifie qu'on a fixé la variable à false.
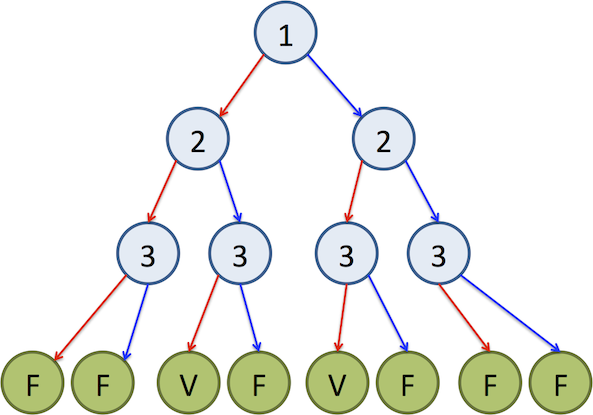
Les algorithmes plus avancés de résolution du problème SAT vont mettre en oeuvre des techniques permettant de couper des branches de l'arbre en détectant en amont qu'une branche conduit à false ou bien en propageant le choix fait pour une variable sur les autres variables.
Bien que l'implémentation de solveurs SAT efficaces soit un domaine de recherche toujours actif
(cf SAT Competitions), la plupart des méthodes modernes
de résolution sont basées sur des variantes de
l'algorithme de Davis-Putnam-Logemann-Loveland (DPLL), introduit en 1962.
Par rapport à l'algorithme de la section précédente, DPLL ne va plus simplement énumérer les possibilités,
mais s'appuyer sur une résolution partielle basée sur deux règles, la propagation unitaire et l'élimination de
littéraux purs, que l'on décrit dans la section suivante.
L'algorithme DPLL repose sur deux règles : l'élimination des littéraux purs et la propagation des clauses unitaires. Ces deux règles sont faciles à comprendre mais ne sont pas triviales à coder et sources de nombreux bugs. Pensez donc toujours à vérifier votre solution en la testant sur différents exemples et en comparant au résultat obtenu par le solver online. Parmi ces deux règles, la propagation des clauses unitaires est de loin la plus efficace. On vous propose donc de vous concentrer d'abord sur celle-ci.
Important: Pour intégrer ces deux règles (décrites plus bas) dans votre solver, vous devrez probablement gérer l'information des clauses dites actives dans la formule. Une clause \(c\) d'une formule \(\Phi\) est active pour le modèle \(m\) si \(c\) ne peut s'évaluer à vrai ou à faux dans \(m\), autrement dit si c.eval(m) retourne null. Seules les clauses actives sont intéressantes : si c.eval(m) vaut true, alors \(\Phi\) est satisfiable si et seulement si les autres clauses de \(\Phi\) s'évaluent à vrai, et si c.eval(m) vaut false, alors \(\Phi\) n'est pas satisfiable par \(m\).
Dans la description de l'algorithme DPLL, le terme clause désignera toujours une clause active.
Une clause est dite unitaire si elle ne contient plus qu'un seul littéral non-assigné : par exemple, la clause \(1\vee 2\vee \neg 3\) est unitaire dans le modèle \(m=\{1\mapsto {\tt false}, 2\mapsto{\tt false}\}\). Si une clause est unitaire, elle ne peut être satisfaite qu'en affectant l'unique valeur qui la rend vraie à son littéral libre. Dans notre exemple, il faut assigner à la variable 3 la valeur false. En pratique, son application entraîne une cascade d'autres clauses unitaires, et évite donc d'explorer une grande part de l'espace de recherche.
Ecrire une méthode boolean pureClauses() qui implémente la propagation des clauses unitaires dans la classe Instance. Cette méthode modifiera le modèle courant, et retournera true si le modèle a été modifié, et false sinon. On veillera à maintenir à jour l'information des clauses actives.
Déposer votre programme TD910.javaIndice. Vous pourrez écrire une méthode boolean isUnit(Model m) dans la classe Clause qui teste si une clause est unitaire dans le modèle m.
Si une variable propositionnelle apparaît seulement dans toutes les clauses sous une seule forme (soit seulement positive, soit seulement négative), alors on dit que cette variable et ses littéraux sont purs. Par exemple, dans la formule \( (1\vee 2\vee 3)\wedge (\neg 1\vee \neg 2)\wedge 3 \), la variable 3 est pure. Les littéraux purs peuvent toujours être affectés d'une manière qui rend toutes les clauses qui les contiennent vraies. Par conséquent ces clauses ne contraignent plus l'espace de recherche, elles ne sont plus actives.
Ecrire une méthode boolean pureLitteralAssign() dans la classe Instance qui effectue cette élimination des littéraux purs en modifiant le modèle courant et retourne true si le modèle a été modifié, et false sinon. On veillera à maintenir à jour l'information des clauses actives.
Déposer votre programme TD910.javaEcrire une méthode void simplify() dans la classe Instance qui exécute les deux règles successivement jusqu'à stabilisation, c'est-à-dire jusqu'à ce que le modèle ne soit plus modifié.
Ajouter cette phase de simplification des instances dans l'algorithme de résolution du problème SAT : avant d'évaluer si une formule est vraie, on procèdera à la simplification de l'instance en question pour éviter des branchements inutiles.
Reprendre les exemples de la partie précédente pour vérifier que le temps de calcul diminue. Tester maintenant votre programme sur les programmes test6.cnf à test10.cnf. Vous pouvez utiliser le programme de test TestQ4.java qui verifie votre solution sur les 10 exemples.
Déposer votre programme TD910.java En allant sur cette page, vous aurez accès au classement pour cette question.L'algorithme naïf de résolution de SAT est clairement correct et complet : il termine toujours et répond toujours la bonne réponse. La preuve de ces propriétés est triviale car l'algorithme naïf correspond à une exploration exhaustive de tous les modèles possibles
L'algorithme DPLL est également complet et correct. Pouvez-vous expliquer pourquoi ? Notamment, expliquer pourquoi l'algorithme termine toujours (et donc pourquoi la fonction simplify termine). Donner une spécification JML de cette fonction qui prouve sa terminaison (on pourra utiliser les mots clés \old et \ensure par exemple).
Nous vous proposons maintenant de comparer l'efficacité de votre solution à celles de vos camarades. Le but est d'obtenir la méthode correcte la plus rapide. Nous allons donc automatiquement tester votre programme sur un ensemble de formules choisies et mesurer le temps d'exécution total et le nombre de réponses correctes.
Nous vous fournissons l'ensemble des fichiers servant au test de votre solveur ainsi qu'un programme de test qui simule ce que fera le script de test automatique. Télécharger donc tests_competition.zip et décompresser le fichier dans le répertoire de base de votre projet (TD910 donc). Cela devrait créer un répertoire tests_competition/ qui contient 50 formules au format CNF. Télécharger également SATCompetition.java qui va exécuter tous les tests, mesurer le temps et afficher le résultat. Le script automatique exécutera les mêmes tests, mais dans un ordre aléatoire. Vous pourrez donc tester votre efficacité à l'aide du programme SATCompetition avant de soumettre.
Pour que vos résultats soient mis à jour, vous devrez déposer votre fichier TD910.java ici:
Dans la suite de ce sujet, nous vous proposons quelques optimisations que vous pouvez ajouter à votre projet pour améliorer votre temps de calcul.
Attention. Il est facile de faire des erreurs lorsqu'on code ces améliorations et de casser la correction du solveur : pensez donc toujours à vérifier que votre solveur donne les bons résultats.
Un moyen de détecter efficacement si une clause \(c\) est unitaire est de garder un décompte des littéraux actifs dans \(c\). Un littéral est dit actif si la variable correspondante n'est pas affectée. Une clause unitaire est donc une clause avec un seul littéral actif. Rajouter donc un champ à la classe Instance pour compter le nombre de littéraux actifs par clause, et maintenez ce nombre à jour lors de l'affectation d'une variable (soit pendant la phase de propagation soit pendant la phase de décision).
Indice. On pourra ajouter à la classe Formula un champ qui associe à chaque variable la liste des clauses dans laquelle elle intervient.
Indice 2. Faites attention à maintenir également à jour la liste des clauses actives.
Les solveurs modernes les plus efficaces utilisent un méchanisme supplémentaire pour résoudre le problème SAT. Il s'agit de l'apprentissage de clauses : Conflict Driven Clause Learning ou CDCL. Intuitivement, l'idée consiste à utiliser les évaluation de la formule à false pour couper dans l'arbre de recherche. Par exemple, pour la formule ...
Pour implémenter cette technique, il faut donc pouvoir :