Dans ce TD, nous allons construire des structures de données classiques
très utilisées dans les algorithmes et applications usuelles.
La première est la structure de liste chaînée qui permet de stocker des listes d'éléments
arbitrairement longues. Elle s'oppose aux tableaux par différents aspects. Tout d'abord, on peut y
ajouter autant d'éléments que l'on veut (du moment qu'il reste de la mémoire dans l'ordinateur)
contrairement aux tableaux qui ont une taille fixée. Ensuite, on peut y insérer des éléments de
manière efficace, sans devoir décaler tous les éléments qui suivent. En contrepartie, on ne peut
accéder directement à un maillon de la chaîne : il faut le retrouver à partir du début.
La seconde est la structure d'arbre binaire. Elle permet d'associer
chaque valeur à deux autres valeurs et, plus efficacement, de retrouver
les valeurs.
Le dernier est la structure de table de hachage. Elle permet d'associer efficacement une valeur
à une autre appelée clef et, tout aussi efficacement, de retrouver cette valeur à partir de la clef.
Par exemple, on peut associer à une chaîne de caractères représentant une variable la valeur stockée
dans cette dernière.
Si vous utilisez Eclipse, commencez par créer un nouveau projet,
nommé par exemple TD45. Le programme principal de ce projet sera mis
dans un fichier TD45.java.
Note: certaines questions sont notées x++). Cela signifie qu'elles
sont optionnelles. Elles ne doivent pas
bloquer votre progression dans le TD.
Listes chaînées
Une liste chaînée est implémentée par une suite de maillons chaînés les uns aux autres : chaque maillon contient
la référence du maillon suivant. Ainsi, avec la référence vers le premier maillon, on peut accéder successivement à tous
les maillons de la chaîne. À la fin de la chaîne, on met la référence du maillon suivant à null.
Pour être exploitable, une liste chaînée contient une information dans chaque maillon.
En plus de la référence du maillon suivant, un maillon contiendra aussi une valeur. Pour l'instant nous considérons que ces valeurs sont simplement des entiers (mais les structures seront facilement généralisables à d'autres types de valeurs).
Par exemple, une liste de longueur trois correspond à la figure suivante :
Écrire dans un fichier Liste.java:
class Liste{
int valeur;
Liste suivant;
Liste(int v, Liste l){
valeur=v;
suivant=l;
}
}
Il s'agit de la déclaration d'un type enregistrement qui combine
un champ valeur de type int
un champ suivant qui contient la référence vers le
maillon suivant (ce champ est donc lui-même de type Liste),
un constructeur qui permet de construire un objet de type Liste (en initialisant ses champs par les paramètres l et v).
On pourra ainsi écrire une déclaration/affectation Liste l = new Liste(3,null); pour déclarer la variable l et lui assigner une nouvelle liste formée d'un seul élément qui vaut 3.
Après cette instruction, l'expression l.valeur vaut
3, et l'expression l.suivant vaut
null.
On peut utiliser cette construction plusieurs fois dans une même
expression, ainsi new Liste(3,new Liste(5,null))
construit une nouvelle liste formé de l'élément 3 suivi de 5.
Écrire dans le fichier TD45.java, une fonction
main (dans la classe TD45):
public static void main(String[] args){
Liste test = new Liste(3,new Liste(5,null));
TC.println(test.valeur);
TC.println(test.suivant.valeur);
}
On peut aussi ré-utiliser une liste déjà connue, disons next, pour lui rajouter un élément en tête :
new Liste(3,next).
Dans notre programme, nous allons écrire les premières fonctions de manipulation de listes chaînées. On fera attention à ce que le temps mis par chaque fonction soit proportionnel à la longueur de la liste sur laquelle elle travaille.
Afin de tester les fonctions que vous allez écrire, placer
dans le programme principal (class TD45{...}) la fonction suivante qui permet d'afficher une liste :
Dans le programme principal, écrire une fonction statique aleatoire qui prend deux arguments entiers max et longueur, et crée une liste aléatoire de longueur longueur d'entiers entre 0 et max. (Math.random() retourne un double de l'intervalle [0,1[.)
La tester avec la fonction principale suivante :
public static void main(String[] args){
Liste test = aleatoire(100,10);
unIntParLigne(test);
}
Déplacer les fonctions aleatoire et unIntParLigne
dans la classe Liste, et tester avec la fonction principale suivante:
public static void main(String[] args){
Liste test = Liste.aleatoire(100,10);
Liste.unIntParLigne(test);
}
Dans la classe Liste écrire une
fonction public int longueur() qui retourne la longueur de la liste,
c'est-à-dire le nombre de maillons dans la chaîne avant d'arriver à la
référence null. On pourra adopter le style suivant pour parcourir une liste chaînée :
if (suivant == null) {...}
else {...}
Tester cette fonction en l'appelant depuis la fonction main:
TC.println("Longueur = "+test.longueur());
Le résultat attendu est:
Longueur = 10
Écrire une fonction public int somme() dans
Liste qui calcule la somme des entiers présents dans une liste chaînée.
Écrire une fonction public String toString() qui retourne les int présents
dans la liste passée en argument sous la forme suivante :
d1; d2; ... ; dk (en respectant les espaces) si la liste
contient les ints d1, d2, ... ,dk.
Écrire une fonction public int[] versTableau() qui construit un tableau (de int) à partir d'une liste chaînée. Les valeurs doivent être dans le même ordre dans la liste et le tableau.
Écrire une fonction public static Liste depuisTableau(int[] x) qui effectue l'opération inverse. Cette fonction prend un tableau en paramètre et retourne une liste.
Tester votre fonction en l'appelant depuis la fonction main:
TC.println(test);
int[] tableau = test.versTableau();
Liste liste = Liste.depuisTableau(tableau);
TC.println(liste);
Remplacer l'argument int[] par int... dans la fonction précédente. Ceci permet de créer une fonction qui prend un nombre variable de paramètres (éventuellement nul) fournis à la fonction dans un tableau. On peut également lui passer un tableau directement, la fonction reste compatible avec l'ancienne signature. Essayer d'utiliser la nouvelle version de depuisTableau pour créer simplement les listes [1;3;4], [1;5;6;7] et [9;56;1;90].
Par exemple, pour créer la première liste, utilisez dans le corps de la fonction main:
Liste liste1 = depuisTableau(1,3,4);
Écrire une fonction pascal qui affiche un triangle de Pascal. La fonction calculera une ligne en fonction de la précédente à l'aide de la formule et prendra le nombre de lignes à afficher en paramètre. On utilisera une liste pour stocker la ligne
courante . Question bonus: pouvez-vous n'utiliser qu'une seule liste ?
Tester cette fonction en l'appelant depuis la fonction main
:
pascal(10);
Le résultat attendu est les dix premières lignes du triangle de Pascal.
Pile et File
Dans cette partie, nous allons implémenter deux autres structures de données : les piles et
les files. Ces structures permettent d'ajouter et de retirer des éléments avec comme différence
que, dans une pile, l'élément retiré est le dernier ajouté et dans une file, l'élément retiré est le premier
ajouté parmi ceux qui restent dans la file. Pour implémenter ces structures, il suffit d'avoir une
liste chaînée. Pour la pile, seule la référence sur le premier maillon est nécessaire alors que pour
la file, il faut aussi connaître la référence sur le dernier maillon afin d'ajouter des éléments en queue
de liste.
Pour cela, créer un type enregistrement PileFile contenant deux références vers des maillons :
l'une vers le premier élément de la liste et l'autre vers le dernier élément de la liste.
Quand la liste est vide, ces deux références doivent valoir null, mais l'objet de type PileFile, lui, n'est pasnull.
Dans le classe PileFile, écrire une fonction estVide() qui renvoie un booleen qui dit si oui ou non la pile ou la file est vide.
Écrire une fonction retirer qui retire un élément du début de la liste et le renvoie;
si la liste est vide, lancer une exception avec throw new RuntimeException("Liste Vide");.
Écrire des fonctions ajouterDebut et ajouterFin qui ajoutent une valeur respectivement
au début et à la fin de la liste. Ainsi, pour avoir une pile, on utilise retirer et
ajouterDebut et pour avoir une file, on utilise retirer et ajouterFin.
Écrire une fonction statique pileFileDeListe qui construit une pile/file
à partir d'une liste chaînée. Il n'est pas nécessaire de dupliquer la liste.
Écrire une fonction concatene(PileFile pf) qui prend une seconde PileFile et
qui concatène la seconde dans la première puis vide la seconde. Par exemple,
si elle est appelée avec [1;2;3] et [4;5;6],
au retour de la fonction, la première contient [1;2;3;4;5;6] et
la seconde est vide. La fonction doit s'exécuter en temps constant.
Arbres Binaires De Recherche
Un arbre binaire diffère d'une liste chaînée
par le fait que chaque noeud contient des références vers deux autres
noeuds au lieu d'un seul.
Plus précisément, nous considérons des arbres binaires de recherche, où les valeurs
sont stockées dans l'ordre pour les rendre plus faciles à trouver.
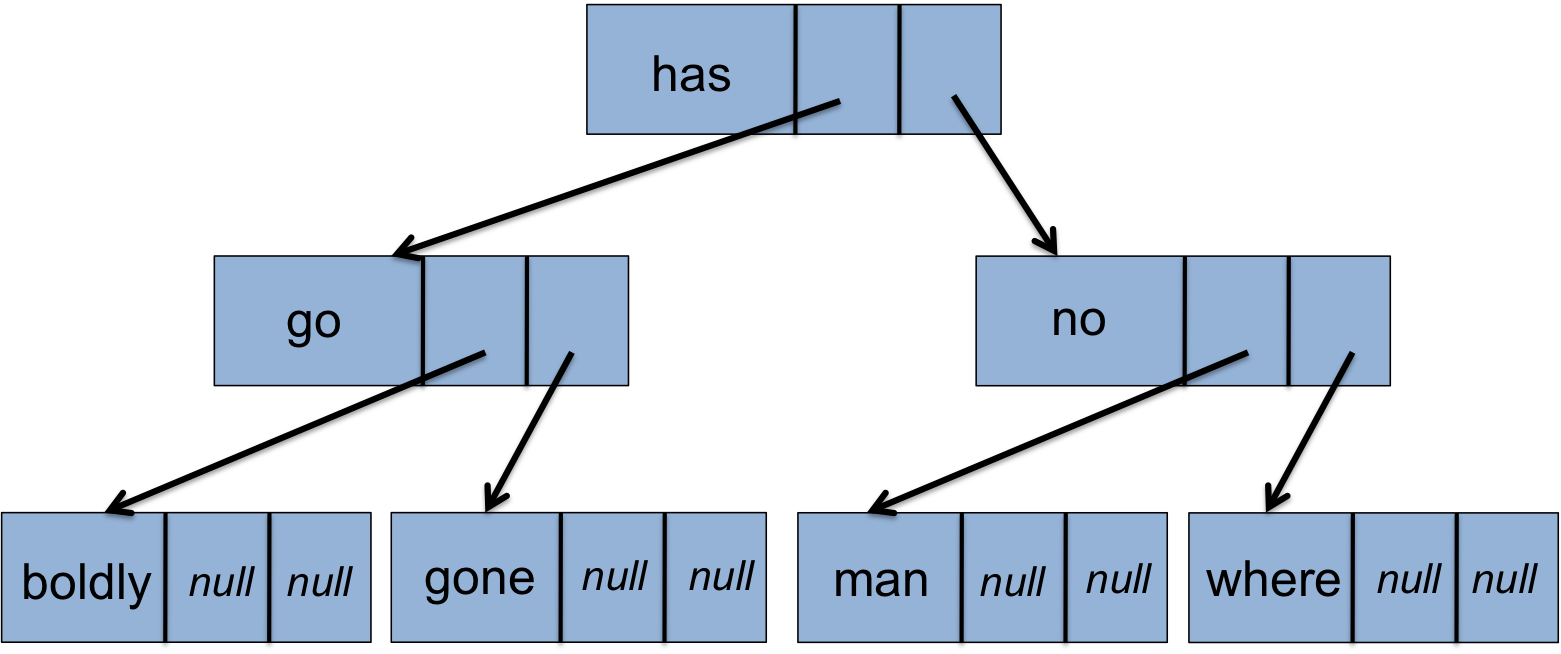
La structure est illustrée par
le dessin suivant :
Le sommet de l'arbre est appelé la racine.
Chaque noeud possède une valeur (de type String)
et des liens vers deux "fils" : l'un à gauche et l'autre à droite.
Notez que tous les noeuds du côté gauche de la racine contiennent
des valeurs inférieures à celle contenue dans celle-ci.
De même, les noeuds du côté droit de la racine contiennent
des valeurs supérieures à celle contenue dans celle-ci (dans
l'ordre lexicographique).
Écrire dans un fichier ArbreBinaire.java:
class ArbreBinaire{
String valeur;
ArbreBinaire gauche;
ArbreBinaire droite;
ArbreBinaire(String v, ArbreBinaire g, ArbreBinaire d){
// à completer
}
}
Il s'agit de la déclaration d'un type enregistrement qui combine
un champ valeur de type String,
deux champs gauche et droite
qui contient la référence vers les enfants,
un constructeur qui permet de construire un objet de
type ArbreBinaire.
Pour construire les trois premiers noeuds de l'arbre ci-dessus, on pourra ainsi écrire: ArbreBinaire b = new ArbreBinaire("has",new ArbreBinaire("go",null,null),new ArbreBinaire("no",null,null))
Après cette instruction, l'expression b.valeur vaut
"has", l'expression b.gauche.valeur vaut
"go" et l'expression b.gauche.gauche vaut
null.
Écrire dans le fichier TD45.java, une fonction
main (dans la classe TD45)
qui construit l'arbre ci-dessus et affiche la valeur
en bas à gauche et en bas à droite de cet arbre.
Écrire dans la classe ArbreBinaire,
une fonction void affiche(){...} qui affiche tous les valeurs
dans l'arbre.
Elle imprime d'abord la valeur à la racine, puis les valeurs situées
à sa gauche, puis celles situées à sa droite.
N'oubliez pas de vérifier que le fils gauche et le fils droit ne sont pas nuls
avant de les afficher (comme gauche.affiche(), par example).
La tester avec la fonction main dans
la classe TD45 pour afficher l'arbre construit ci-dessus.
public static void main(String[] args){
ArbreBinaire b = ...;
b.affiche();
}
Le résultat attendu est:
has
go
boldly
gone
no
man
where
Écrire dans la classe ArbreBinaire,
une fonction void afficheTrier(){...} qui affiche toutes les valeurs
dans l'arbre dans l'ordre trié.
Elle imprime d'abord les valeurs du sous-arbre
gauche, puis la valeur située à la racine, puis celles du sous-arbre
droit.
La tester avec la fonction main. Le résultat attendu est:
boldly
go
gone
has
man
no
where
Écrire dans la classe ArbreBinaire,
une fonction boolean recherche(String v){...} qui
recherche un noeud avec la valeur v dans l'arbre.
Notez que le fait que l'arbre soit trié va nous permettre de faire
une recherche efficace, ne traversant qu'une très petite partie de l'arbre.
Nous commençons par comparer la valeur recherchée à la valeur contenue dans
la racine, si elle lui est égale, nous retournons true,
si elle est plus petite, nous poursuivons la recherche dans le sous-arbre gauche,
si elle est supérieure, nous poursuivons la recherche dans le sous-arbre droit.
Pour comparer une chaîne s avec
une chaîne t nous allons utiliser s.compareTo(t)
qui retourne:
un entier négatif si s est plus petit que t,
un entier positif si s est plus grande que t, et
l'entier 0 si s et t sont égales.
Pour tester, cherchez les valeurs "to" et "boldly" dans l'arbre ci-dessus,
et afficher les resultats.
Dans le premier cas, on doit obtenir false et dans le second,
true.
Écrire dans la classe ArbreBinaire,
une fonction void ajouter(String v){...} qui
ajoute une noeud avec la valeur v dans l'arbre.
Ce noeud sera ajouté au bas de l'arbre à l'endroit correct
pour préserver la propriété de tri des valeurs selon l'ordre
lexicographique.
Nous commençons par comparer la donnée valeur à la valeur à la racine,
si elle est plus petite, nous l'ajouterons à gauche, si elle est supérieure,
nous l'ajouterons à droite. Si elle sont égales, nous ne modifions pas l'arbre
Pour tester, ajouter les valeurs "to" et "before" à l'arbre ci-dessus,
et afficher l'arbre avec affiche. Le résultat attendu est:
has
go
boldly
before
gone
no
man
where
to
Écrire dans la classe ArbreBinaire,
une fonction ArbreBinaire retirer(String v){...} qui
cherche le noeud contenant la valeur v dans l'arbre
et retourne l'arbre sans ce noeud.
Si le nœud que nous voulons supprimer est une feuille de l'arbre,
sa suppression est facile.
Toutefois, si il est situé au milieu de l'arbre, nous aurons besoin
de le remplacer par un autre nœud.
Ce noeud sera soit le fils le plus à droite du sous-arbre gauche du noeud
à supprimer soit le fils le plus à gauche de son sous-arbre droit.
Noter qu'il faut considérer de nombreux cas et utiliser des
fonctions auxiliaires.
Nous vous conseillons d'abord écrire une fonction auxiliaire pour la suppression de la racine d'un arbre.
Vous pouvez ensuite l'utiliser pour implémenterretirer.
Testez votre fonction en supprimant "go" et "man" de l'arbre ci-dessus.
Afficher l'arbre et verifier la resultat.
Spécification des invariants de structures de données
Quand on utilise des structures de données complexes, il devient important de spécifier
et de vérifier que nous préservons les propriétés de ces structures, pour éviter de
laiser des erreurs dans nos programmes.
Une méthode consiste à écrire invariants de notre structure de données sous la forme
de fonctions booléennes que nous pouvons appeler pour vérifier l'état de la structure.
Nous allons spécifier et vérifier deux de ces invariants pour nos arbres binaires.
Tout d'abord, nous allons vérifier que la taille de l'arbre est conforme à notre attente,
puis ensuite, nous vérifierons que les valeurs contenues dans les noeuds sont triés.
Ajouter dans la classe ArbreBinaire, un champ
taille qui représente le nombre de noeuds dans l'arbre.
class ArbreBinaire{
String valeur;
ArbreBinaire gauche;
ArbreBinaire droite;
int taille;
...
}
Modifier le constructeur ArbreBinaire et toutes les fonctions
dans ArbreBinaire qui modifient l'arbre pour mettre à jour correctement le champ taille.
Les tester dans main avec l'arbre construit ci-dessus.
public static void main(String[] args){
ArbreBinaire b = ...;
TC.println(b.taille);
b.ajouter("xxx");
TC.println(b.taille);
...
}
Ajouter dans la classe ArbreBinaire, une fonction
int calculerTaille() qui calcule le nombre de noeuds dans l'arbre.
Ajouter dans la classe ArbreBinaire, une fonction
boolean verifierTaille() qui verifie pour chaque noeud dans l'arbre que le champ
taille est égal au resultat de fonction calculerTaille.
Les tester avec les arbre construits plus haut, mais aussi avec des arbres
mal-formés, comme par exemple&nbps;:
public static void main(String[] args){
ArbreBinaire b = new ArbreBinaire("has",new ArbreBinaire("go",null,null),new ArbreBinaire("no",null,null));
b.verifierTaille();
b.taille = 10;
b.verifierTaille();
b.ajouter("before");
b.verifierTaille();
}
Ajouter dans la classe ArbreBinaire, une fonction
boolean verifierInf(String v) qui vérifie que tous les valeurs des
noeuds de l'arbre sont plus petites que la valeur v.
Ajouter dans la classe ArbreBinaire, une fonction
boolean verifierSup(String v) qui vérifie que tous les valeurs des
noeuds de l'arbre sont plus grandes que la valeur v.
Ajouter dans la classe ArbreBinaire, une fonction
boolean verifierTrier() qui vérifie que les valeurs des noeuds
de l'arbre sont triées suivant l'ordre lexicographique.
Pour chaque nœud, elle vérifiera que les valeurs dans le sous-arbre gauche
sont plus inférieures à la valeur de la racine et inversement pour les noeuds
du sous-arbre droit.
Les tester avec les arbre construit ci-dessus, mais aussi avec des arbres mal-triées, par exemple:
ArbreBinaire b = new ArbreBinaire("to",new ArbreBinaire("boldly",null,null),new ArbreBinaire("go",null,null));
b.verifierTrier();
ArbreBinaire b1 = new ArbreBinaire("go",new ArbreBinaire("boldly",null,null),new ArbreBinaire("to",null,null));
b1.verifierTrier();
b1.ajouter("where");
b1.verifierTrier();
Spécification et verification des invariants avec JML
Les invariants tels que verifierTaille() et verifierTrier
doivent être contrôlés systématiquement: après le constructeur, avant et après chaque appel d'une méthode. Insérer ces tests partout peut donc être fastidieux.
Nous allons utiliser JML (en particulier l'outil jml4c) qui permet d'injecter automatiquement ces contrôles dans notre programme.
Télécharger jml4c.jar et jml4rt.jar dans le même dossier que vos programmes (TD45, ArbreBinaire).
Écrire dans la classe ArbreBinaire un nouvel invariant JML
qui dit que la valeur de la variable taille est toujours supérieure à 0:
class ArbreBinaire{
String valeur;
ArbreBinaire gauche;
ArbreBinaire droite;
int taille;
//@ invariant (taille > 0);
...
}
Les commentaires commençant par //@ sont des commentaires spéciaux qui seront lus et compris par JML et automatiquement vérifiés lors de l'exécution du programme.
Pour vérifier cet invariant, nous allons utiliser l'outil jml4c qui permet d'insérer les tests de contrôle de l'invariant dans le code. Pour cela, ouvrir un terminal en cliquant sur l'icône .
Il faut compiler le programme programme (avec l'invariant) au moyen de la commande:
java -jar jml4c.jar -cp "jml4c.jar:." TD45.java
Puis on l'exécute par:
java -cp "jml4rt.jar:." TD45
Si notre programme préserve l'invariant, nous verrons les résultats normaux à la sortie. Sinon, nous verrons une erreur. Par exemple, modifier l'invariant ci-dessus pour dire que taille est toujours supérieure à 1.
//@ invariant (taille > 1);
Vous verrez une erreur qui dit que l'invariant n'était pas satisfait par la class ArbreBinaire:
Exception in thread "main" org.jmlspecs.jml4.rac.runtime.JMLInvariantError:
By method ArbreBinaire.@post
Regarding specifications at
File "/Users/karthik/Desktop/polytechnique/INF321/TD45/solutions/./ArbreBinaire.java", line 9, character 18
With values
taille: 1
...
Ajouter dans la classe ArbreBinaire deux invariants qui vérifient que les expressions verifierTaille() et verifierTrier()
sont toujours vraies. Les tester avec les arbre construits ci-dessus, mais aussi avec des arbres mal-triés.
Avec JML, nous pouvons parfois écrire des invariants complexes directement, sans l'aide de fonctions comme verifierTaille. Ajouter dans la classe ArbreBinaire, un invariant qui dit que le taille est toujours 1 plus le taille du sous-arbre gauche (si il n'est pas null) plus le taille du sous-arbre droit (si il n'est pas null).
Pour verifier avec JML que l'arbre est trié, nous allons d'abord vérifier que tous les valeurs de l'arbre sont comprises entre deux valeurs, un minimum et un maximum. Ajouter dans la classe ArbreBinaire deux champs min et max qui représentent la plus petite et la plus grande valeur dans l'arbre.
class ArbreBinaire{
String valeur;
String min;
String max;
...
}
Modifiez le constructeur et les méthodes (ajouter,retirer) afin de
mettre à jour ces champs.
Ajouter un invariant qui dit que la valeur à la racine est toujours entre min
et max. (Rappelez-vous que pour comparer deux chaînes on utilise la méthode compareTo).
Verifier cet invariant avec jml4c.
Ajouter un invariant qui dit que l'intervalle [min,max] à la racine
contient les intervalles dans les sous-arbres gauche et droit.
Verifier cet invariant avec jml4c.
Vérifier que l'arbre est trié, en ajoutant un invariant
qui dit que le max du sous-arbre gauche est inférieur à la valeur
de la racine, et que le min du sous-arbre droit est supérieur à la valeur
à la racine. Testez-le avec des arbres qui sont triés et non triés.
Pouvez-vous prouver (à la main) que la combinaison des invariants que nous avons définis est suffisante
pour établir que l'arbre est trié?
Tables de hachage
Principe
Une table de hachage est une collection de données où chaque entrée est un couple (clef,valeur).
L'intérêt d'une table de hachage, par rapport à une simple liste, est que si l'on connaît la clef,
on peut savoir si la collection contient cette clef et récupérer la valeur associée en temps moyen
constant. Par exemple, si l'on déclare un type enregistrement Eleve avec comme champs: nom, prénom, matricule
etc..., et que l'on range des objets de ce type dans une table de hachage en prenant le matricule comme clef,
il sera alors possible d'obtenir la fiche d'un élève à l'aide du matricule. S'il l'on ajoute une
seconde table pour laquelle la clef est le nom, il sera aussi possible de chercher la fiche d'un élève
par son nom.
Une seule valeur est associée à une clef, et associer une nouvelle valeur à une clef
déjà présente dans la table écrase l'ancienne valeur.
Implémenter une table de hachage est trivial dans le cas où les clefs
sont des entiers pris dans un intervalle [0,n] quand n n'est
pas trop grand. Dans ce cas la table de hachage est
un tableau et la case i contient la valeur associée à la clef i et null
si aucune valeur ne lui est associée.
Les tables de hachage pour tout type se ramènent au cas précédent : on utilise
une fonction de hachage qui à une clef associe un int. La fonction de hachage doit
être telle que si l'on prend deux valeurs égales (au sens sémantique, mais cela peut être deux références différentes),
leurs valeurs de hachage doivent aussi
être égales. En pratique, pour que la structure soit efficace, on demande
beaucoup plus à la fonction de hachage et en particulier, on veut
que les valeurs qu'elle donne pour les valeurs rencontrées pendant
l'exécution du programme soient les plus éloignées possible les unes
des autres.
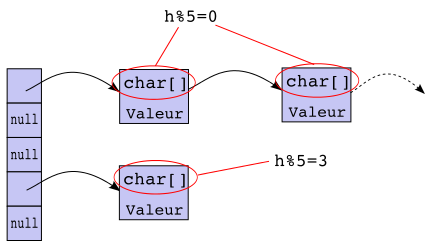
Une fois cette bonne fonction de hachage h trouvée, on procède de la manière suivante.
On commence par créer un tableau à n cases et si l'on veut ajouter l'entrée
(clef,valeur), on stocke le couple (clef,valeur) dans la case h(clef) mod n
du tableau. Comme il peut y avoir plusieurs valeurs dans la même case, chaque case contient une liste de couples (clef,valeur).
La structure est illustrée par le dessin suivant :
Les opérations sur la table de hachage sont donc les suivantes :
ajout(clef,valeur) : considérer la liste présente dans la case
h(clef) mod n, chercher si clef est dans la liste et dans ce cas
lui associer la nouvelle valeur ; sinon ajouter le couple (clef,valeur)
à la liste
cherche(clef) : considérer la liste présente dans la case
h(clef) mod n, chercher si clef est dans la liste et dans ce cas
retourner l'entrée associée ; sinon retourner null
On notera que dans ce cas, plus la table est pleine, et plus les listes se remplissent
et moins le temps de recherche est constant, même avec un bon hachage. Ainsi, si le
tableau a pour taille n, mais que la table contient n2 entrées, au mieux,
chaque liste a n éléments et les opérations ci-dessus
sont au mieux en temps
n. Pour cela, quand la table commence à être trop remplie, il
est nécessaire de faire un rehachage des entrées : on agrandit le tableau
et on répartit à nouveau les données à l'aide de la fonction de hachage.
Implémentation
Dans un premier temps, nous allons implémenter une table de hachage
dont le type des clefs est char[] et le type des valeurs est int. La fonction de hachage sera la suivante :
static int hashCode(char[] clef) {
int hash = 0;
for (int i = 0; i < clef.length; i=i+1) {
hash = clef[i] + (hash << 6) + (hash << 16) - hash;
}
return hash;
}
Attention, cet appel peut retourner une valeur négative
et les ordinateurs ne calculent pas les moduli comme les mathématiciens : x mod k
retourne une valeur entre -k+1 et 0 quand x est négatif.
On calculera le modulo avec la fonction suivante :
static int modulo(int x,int k) {
int valeur = x%k;
if (valeur<0) return valeur+k;
else return valeur;
}
Déclarer un type enregistrement Entree avec un champ clef de type
char[] et un champ valeur de type int,
avec un constructeur qui initialise les deux champs avec ses paramètres.
Tester ce constructeur en l'appelant depuis la fonction main:
char[] clef1 = {'f','o','o'};
int valeur1 = 42;
Entree e1 = new Entree(clef1,valeur1);
char[] clef2 = {'b','a','r'};
int valeur2 = 666;
Entree e2 = new Entree(clef2,valeur2);
Il va falloir stocker des listes chaînées d'objets de type Entree. Déclarer un type enregistrement ListeEntree dans ce but.
Pour créer une ListeEntree, utiliser dans le corps de la fonction main:
ListeEntree l = new ListeEntree(e1, new ListeEntree(e2, null));
Déclarer un type enregistrement TableDeHachage avec un champ
(appelons-le par exemple entrees) de type ListeEntree[] (pour contenir la liste des entrées) et un champ taille
contenant le nombre d'entrées (qui n'a rien à voir avec la taille
du tableau - on rappelle que la taille d'un tableau t est donnée
par l'expression t.length et qu'il n'est par conséquent pas utile
de la stocker).
Pour créer une TableDeHachage avec un tableau qui a taille 10, utiliser dans le corps de la fonction main:
TableDeHachage t = new TableDeHachage(10);
Écrire dans la classe TableDeHachage une fonction
indiceDeHachage qui prend une clef (de
type char[]) et qui renvoie un entier. Celui-ci
sera l'indice indiquant dans quelle case de la table devrait se
trouver une entrée associée à la clef.
Tester cette fonction en l'appelant depuis la fonction main avec une table à 10 cases.
Pour la clef "foo", le résultat attendu est 0,
et pour "bar", 7.
Écrire une fonction egales qui teste
si deux char[] sont égaux.
Écrire une fonction
ajouter
qui ajoute une entrée dans la table de hachage (penser à mettre à jour le champ
taille). S'il existe une ancienne valeur associée à cette clef la fonction retourne l'entrée et l'ancienne valeur est remplacée par la nouvelle. Sinon, la fonction renvoie null.
Ajouter un constructeur TableDeHachage(Entree[] initial). Toutes les entrées de initial doivent être ajoutées à la table construite. Celle-ci sera faite d'un tableau de 2*initial.length cases.
Indications:
on pourra appeler la fonction ajouter de votre programme (appelé par exemple TD45) par TD45.ajouter(...).
on pourra passer par une table de hachage temporaire crée avec le constructeur TableDeHachage(2*initial.length).
Écrire une fonction public String toString() qui retourne le contenu de la table de hachage, en mettant sur une ligne le contenu de chaque liste du tableau. Plus précisément, la ligne commencera par l'indice de hachage (le numéro de la case) suivie de la suite des entrées (clef, valeur). Le caractère de retour à ligne est '\n', que l'on peut insérer dans une chaîne de caractères comme par exemple "une ligne\nune autre".
Tester votre fonctions en l'appelant depuis la fonction main:
t.ajouter(e1);
t.ajouter(e2);
TC.println(t);
Écrire une fonction
cherche
qui retourne l'entrée associée à la clef ou null si aucune
valeur ne lui est associée.
Tester cette fonction en l'appelant depuis la fonction main:
TC.print("Searching for ");
TC.print(clef1);
Entree ch = t.cherche(clef1);
if (ch == null) TC.println(": Not found");
else TC.println(": Found");
Écrire une fonction
supprimer
qui supprime de la table une entrée donnée par sa clef. Cette fonction retournera
l'entrée supprimée ou null si la clef n'est pas associée.
Écrire une fonction
rehache
qui effectue un rehachage des entrées de la table dans un tableau
dont la taille est celle de l'ancien tableau plus un entier passé en paramètre.
Tester cette fonction en l'appelant depuis la fonction main:
t.rehache(3);
TC.println(t);
Modifier le code de ajouter pour provoquer un rehachage
automatique quand la table a plus d'entrées que trois-quarts
de la taille du tableau.
Le nombre de cases que l'on rajoutera au tableau sera la moitié (arrondie à l'entier supérieur) de son nombre de cases actuel.
Indication:
On calcule la partie entière supérieure de a/b (⌈a/b⌉) avec (a+(b-1))/b pour a et b positifs.
Pourquoi arrondit-on à la partie entière supérieure de la moitié ?
Tester cette fonction en l'appelant depuis la fonction main:
TableDeHachage tab = new TableDeHachage(1);
TC.println(tab.entrees.length);
tab.ajouter(e1);
TC.println(tab.entrees.length);
tab.ajouter(e2);
TC.println(tab.entrees.length);
Écrire une fonction
entrees
qui retourne un tableau contenant les Entree présentes dans la table de hachage.
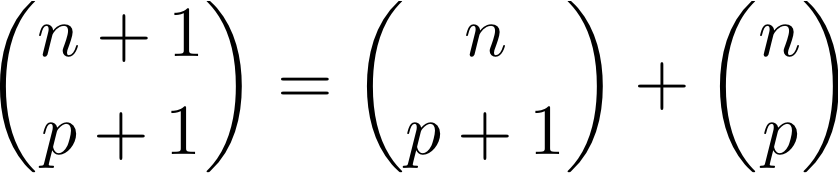 et prendra le nombre de lignes à afficher en paramètre. On utilisera une liste pour stocker la ligne
courante . Question bonus: pouvez-vous n'utiliser qu'une seule liste ?
et prendra le nombre de lignes à afficher en paramètre. On utilisera une liste pour stocker la ligne
courante . Question bonus: pouvez-vous n'utiliser qu'une seule liste ?